1. ResNet이란?
MicroSoft에서 개발한 알고리즘으로 "Deep Residual Learning for Image Recognition"이라는 논문에서 발표하였습니다. ResNet의 핵심은 깊어진 신경망을 효과적으로 학습하기 위한 방법으로 Residual이라는 개념을 고안하였습니다. 일반적으로 신경망이 깊어질수록 성능이 좋아질거 같지만 일정한 단계에 다다르면 오히려 성능이 나빠지는 문제를 해결하기 위해 Residual Block을 도입하였습니다.
이러한 개념이 필요한 이유는 2014년에 공개된 GoogLeNet은 Layer가 22개로 구성된 것에 비해 ResNet은 Layer가 총 152개로 구성되어 기울기 소멸 문제가 발생할 수 있기 때문입니다. 따라서, Shortcut을 두어 기울기 소멸 문제를 방지했다고 이해하면 됩니다.
2. ResNet의 Block

위의 그림에서 Plain Network에서는 Convolution Layer를 단순하게 쌓는다면, ResNet는 Block 단위로 쌓는 구조임을 알 수 있다. 각 Block은 Residual Block이라 한다.
2-1) Residual Block
Residual Block이란 "입력값 그대로 다음 Block에 더해주는 구조"를 가진 Block입니다. 이때, 핵심 아이디어는 학습할 때 전체 출력값이 아니라 입력과 출력의 차이 즉, 잔차(Residual)만 학습하자는 것입니다.

Residual Block에서는 연산 $f(x)$를 수행한 뒤 Input $x$를 더해준다. 이를 Skip Connection(Shortcut, Identity mapping)이라고 한다.
※ Skip Connection(Shortcut, Identity mapping)
Skip Connection이란 신경망의 한 Layer의 출력을 다음 Layer로 바로 연결하는 것을 의미한다. 즉, 어떤 연산을 건너뛰고 입력 데이터를 나중 Layer로 직접 전달하는 연결방식이다.
이를 통해 기울기 소멸 문제와 정보 손실 문제 등을 해결할 수 있다.
- 기울기 소멸 문제 : 역전파 과정에서 역방향으로 진행할수록 Gradient가 0이 되어 기울기 소멸 문제가 발생하는데 Skip Connection을 사용하면 입력 $x$를 그대로 전달하므로 $\frac{\partial y}{\partial x} = \frac{\partial F(x)}{\partial x} + 1$이 되기 때문에 최소 기울기 1이 항상 보장된다 => 기울기 소멸이 되지 않는다
- 정보 손실 문제 : 학습 과정에서 초기 입력 적보가 직접 보전되어 다음 Layer로 전달되기 때문에 초기 입력에 포함된 저수준의 정보가 사라지지 않게 된다.
2-2) Bottleneck Block
하지만, Residual Block을 계속 쌓게되면 Parameter 수가 너무 많아진다. 따라서 이를 해결하기 위해 Bottlenect Block을 두어 사용한다. (Resnet34: 기본 블록, 9.32M parameters, ResNet50 : Bottleneck Block, 6.96M Parameters)
Bottleneck Block은 ResNet-50 이상에서 사용하는 구조로, 기본 Residual Block과 동일하게 $f(x) + x$ 구조를 따르지만 $f(x)$의 내부 구조를 최적화한 것이다.
아래 그림에서 3x3 Convolution Layer 앞뒤로 1x1 Convolution Layer가 붙어있는데, 이를 통해 Channel 수를 조절하면서 차원을 줄였다가 늘리는 것이 가능하기 때문에 Parameter를 줄일 수 있다.

2-3) Down Sample
Feature map의 크기를 줄이기 위한 것으로 Pooling과 같은 역할을 한다고 이해하면 된다.
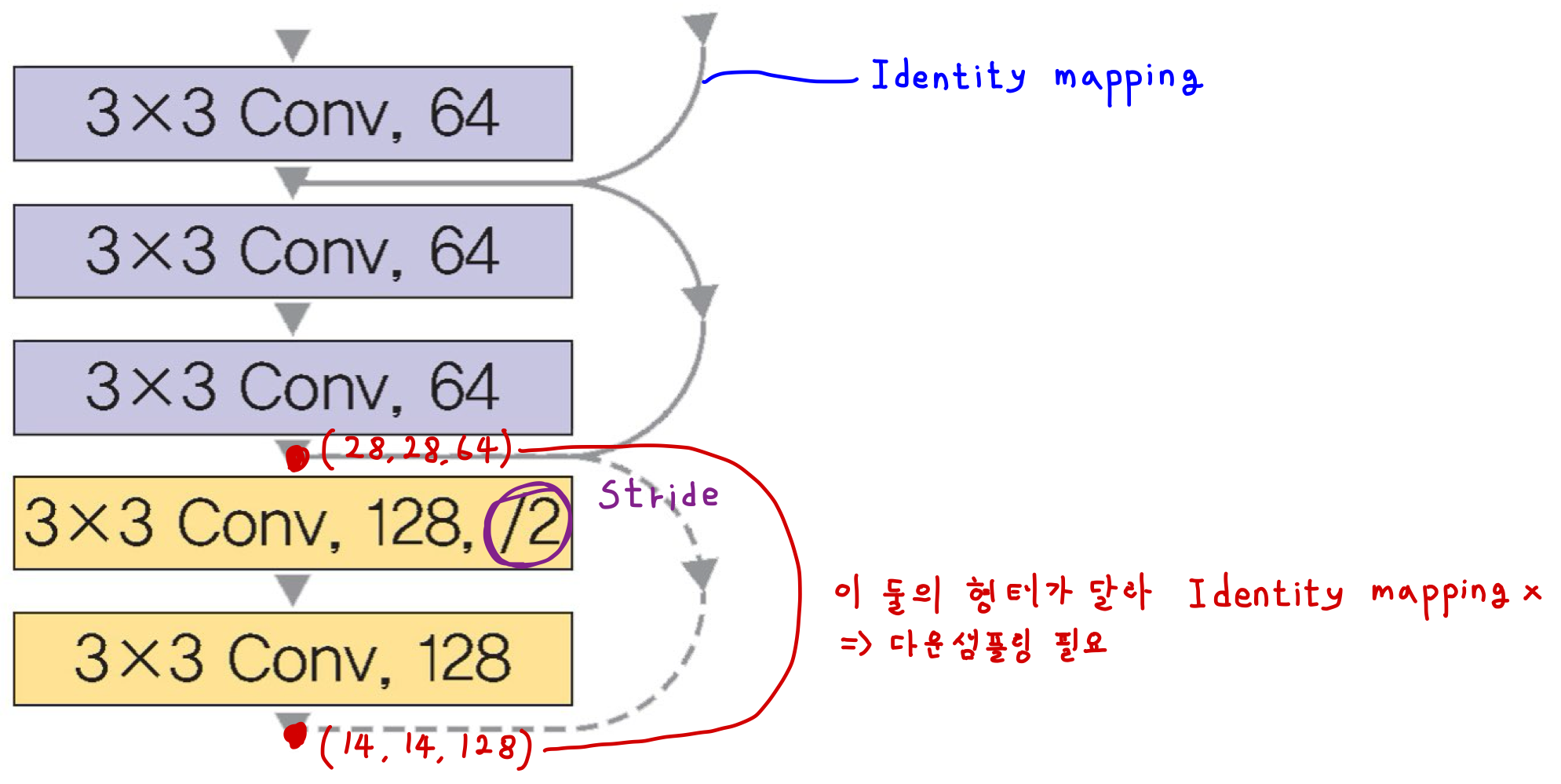
위 그림에서 보라색 블록의 Feature Map Size가 (28, 28, 64)라고 하자.
보라색 블록의 마지막 합성곱층을 통과하고 Skip Connection까지 완료한 Feature Map의 크기도 (28, 28, 64)다.
이때, 노란색 블록의 시작 지점의 Channel 수는 128로 늘어났고, / 2 즉, stride가 2로 늘어나 (14, 14, 128)로 바뀐다는 것을 알 수 있다. 즉, 보라색 블록과 노란색 블록의 Shape이 다른데 이들 간의 형태를 맞추지 않으면 Skip Connection을 할 수 없다.
따라서, Down Sample이 필요하다.

참고로 입력과 출력의 형태가 같도록 맞추기 위해서는 Stride 2를 가진 1x1 Convolution Layer 계층을 하나 연결해주면 된다.
여기서 입력과 출력의 차원이 동일하지 않고 입력의 차원을 출력에 맞추어 변경해야하는 것을 Projection Short Cut 또는 합성곱 블록이라 한다.
3. ResNet PyTorch 예제
1) 필요한 라이브러리 호출
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
from torch.utils.data import DataLoader, Dataset
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import copy
# namedtuple
# 튜플의 성질을 갖고 있는 자료형이지만 index뿐만 아니라 Key 값으로 데이터에 접근 할 수 있다
from collections import namedtuple
import os
import random
import time
import cv2
from PIL import Image
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
2) 데이터 전처리 정의
size = 224
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
batch_size = 32
class ImageTransform():
def __init__(self, resize, mean, std):
self.data_transform = {
'train' : transforms.Compose([
transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean,std)
]),
'val' : transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean,std)
])
}
def __call__(self, img, phase):
return self.data_transform[phase](img)3) 데이터 셋 준비
cat_directory = '../data/dogs-vs-cats/Cat/'
dog_directory = '../data/dogs-vs-cats/Dog/'
cat_images_filepaths = sorted([os.path.join(cat_directory, f) for f in os.listdir(cat_directory)])
dog_images_filepaths = sorted([os.path.join(dog_directory, f) for f in os.listdir(dog_directory)])
images_filepaths = [*cat_images_filepaths, *dog_images_filepaths]
correct_images_filepaths = [i for i in images_filepaths if cv2.imread(i) is not None]
random.seed(42)
random.shuffle(correct_images_filepaths)
train_images_filepaths = correct_images_filepaths[:400]
val_images_filepaths = correct_images_filepaths[400:-10]
test_images_filepaths = correct_images_filepaths[-10:]이미지에 대한 Label 구분
class DogvsCatDataset(Dataset):
def __init__(self, file_list, transforms=None, phase='train'):
self.file_list = file_list
self.transform = transforms
self.phase = phase
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
img_path = self.file_list[idx]
img = Image.open(img_path)
img_transformed = self.transform(img, self.phase)
label = img_path.split('/')[-1].split('.')[0]
if label == 'dog':
label = 1
elif label == 'cat':
label = 0
return img_transformed, label이미지 데이터셋, 데이터 로더 정의
train_dataset = DogvsCatDataset(train_images_filepaths, transforms=ImageTransform(size, mean, std), phase='train')
val_dataset = DogvsCatDataset(val_images_filepaths, transforms=ImageTransform(size, mean, std), phase='val')
train_loader = DataLoader(train_dataset, batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size, shuffle=False)
dataloader_dict = {'train' : train_loader, 'val':val_loader}4) ResNet Block 정의
기본 Residual Block
# Input Shape : (224, 224, 3)
def BasicBlock(nn.Module):
# ResNet에서 병목블록을 정의하기 위한 hyper parameter
# Bottleneck block이 아니기 때문에 expansion = 1
expansion = 1
def __init__(self, in_channels, out_channels, stride, downsample=False):
super().__init__()
# 3x3
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1, bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
# 3x3
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1, bias=True)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
# downsample을 한다면 1x1 Convolution Layer를 둬서 입력의 차원을 출력의 차원에 맞춘다
if downsample :
conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, bias=False)
bn = nn.BatchNorm2d(out_channels)
downsample = nn.Sequential(conv, bn)
else:
downsample = None
self.downsample = downsample
def forward(self, x):
i = x
x = self.conv1(x)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
if self.downsample is not None:
i = self.downsample(i)
# Identity Mapping
# 저장된 초기 입력을 출력 x에 더함
x += i
x = self.relu(x)
return x
Bottleneck Block 정의
ResNet에서 더 깊은 네트워크(ResNet50, 101, 152 등)을 구현하기 위해 사용되는 Block
class Bottleneck(nn.Module):
# ResNet에서 병목블록을 정의하기 위한 hyper parameter
expansion = 4
# Bottleneck Block : 3x3 합성곱 앞뒤로 1x1 합성곱을 배치하여 채널 수 조정
def __init__(self, in_channels, out_channels, stride = 1, downsample = False):
super().__init__()
# 1x1 Convolution Layer로 차원 축소
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
# 3x3 Convolution Layer로 특징 추출
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 다음 layer의 채널수와 맞추기 위해 expansion * out_channels
# 채널 수가 out_channels * 4가 되도록 설계
# 1x1 Convolution Layer로 채널수 복원
self.conv3 = nn.Conv2d(out_channels, self.expansion*out_channels, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*out_channels)
self.relu = nn.ReLU(inplace=True)
if downsample:
conv = nn.Conv2d(in_channels, self.expansion*out_channels, kernel_size=1, stride=stride, bias=False)
bn = nn.BatchNorm2d(self.expansion * out_channels)
downsample = nn.Sequential(conv, bn)
else:
downsample = None
self.downsample = downsample
def forward(self, x):
i = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
if self.downsample is not None:
i = self.downsample(i)
x += i
x = self.relu(x)
return x5) ResNet 정의
ResNet Config
ResNetConfig = namedtuple('ResnetConfig', ['block', 'n_blocks', 'channels'])
resnet18_config = ResNetConfig(block=BasicBlock,
n_blocks=[2,2,2,2],
channels=[64,128,256,512])
resnet34_config = ResNetConfig(block=BasicBlock,
n_blocks=[3,4,6,3],
channels=[64,128,256,512])
# ResNet50 이상부터는 Bottleneck Block 사용
resnet50_config = ResNetConfig(block=Bottleneck,
n_blocks=[3,4,6,3],
channels=[64,128,256,512])
resnet101_config = ResNetConfig(block=Bottleneck,
n_blocks=[3,4,23,3],
channels=[64,128,256,512])
resnet152_config = ResNetConfig(block=Bottleneck,
n_blocks=[3,8,36,3],
channels=[64,128,256,512])class ResNet(nn.Module):
def __init__(self, config, output_dims, zero_init_residual=False):
super().__init__()
# 앞서 정의한 Config에 맞는 Block, Block수, Channel 수
block, n_blocks, channels = config
self.in_channels = channels[0]
# 초기 층
# Block 크기 = Channel 크기 = 4
assert len(n_blocks) == len(channels) == 4
# (3, 224, 224) -> (64, 112, 112)
self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace=True)
# (64, 112, 112) -> (64, 56, 56)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# ResNet Block 층
# get_resnet_layer()를 통해 각 층에 맞는 블록을 반복적으로 쌓는다
# 크기는 유지하면서 Channel수만 변경
self.layer1 = self.get_resnet_layer(block, n_blocks[0], channels[0])
self.layer2 = self.get_resnet_layer(block, n_blocks[1], channels[1], stride=2)
self.layer3 = self.get_resnet_layer(block, n_blocks[2], channels[2], stride=2)
self.layer4 = self.get_resnet_layer(block, n_blocks[3], channels[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(self.in_channels*1*1, output_dims)
# Residual Branch 마지막에 있는 BN을 0으로 초기화해서 다음 레지듀얼 분기를 0에서 시작할 수 있도록 만든다.
# 논문에 의하면 BN을 0으로 초기화할 경우 모델 성능이 0.2~0.3% 향상
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
# 블록을 추가하기 위한 함수
def get_resnet_layer(self, block, n_blocks, channels, stride=1):
layers = []
if self.in_channels != block.expansion * channels:
downsample = True
else:
downsample = False
layers.append(block(self.in_channels, channels, stride, downsample))
for i in range(n_blocks):
layers.append(block(block.expansion * channels, channels))
self.in_channels = block.expansion * channels
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x) # 224x224
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x) # 112x112
x = self.layer1(x) # 56x56
x = self.layer2(x) # 28x28
x = self.layer3(x) # 14x14
x = self.layer4(x) # 7x7
x = self.avgpool(x) # 1x1
h = x.view(x.shape[0], -1)
x = self.fc(h)
return x6) ResNet50, Loss Function, Optimizer 정의
OUTPUT_DIM = 2
model = ResNet(resnet50_config, OUTPUT_DIM)
optimizer = optim.Adam(model.parameters(), lr=1e-7)
criterion = nn.CrossEntropyLoss()7) Accuracy, Train, Validation 함수 정의
Accuracy 측정 함수
def calculate_topk_accuracy(y_pred, y, k=2):
with torch.no_grad():
batch_size = y.shape[0]
_, top_pred = y_pred.topk(k, 1)
# transpose
top_pred = top_pred.t()
correct = top_pred.eq(y.view(1, -1).expand_as(top_pred))
correct_1 = correct[:1].reshape(-1).float().sum(0, keepdim = True)
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim = True)
acc_1 = correct_1 / batch_size
acc_k = correct_k / batch_size
return acc_1, acc_k
모델 학습 함수
def train(model, iterator, optimizer, criterion, device):
epoch_loss = 0.0
epoch_acc_1 = 0.0
epoch_acc_5 = 0.0
model.train()
for (x, y) in iterator:
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
acc_1, acc_5 = calculate_topk_accuracy(y_pred, y, k=2)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc_1 += acc_1.item()
epoch_acc_5 += acc_5.item()
epoch_loss = epoch_loss / len(iterator)
epoch_acc_1 = epoch_acc_1 / len(iterator)
epoch_acc_5 = epoch_acc_5 / len(iterator)
return epoch_loss, epoch_acc_1, epoch_acc_5
모델 평가 함수
def evaluate(model, iterator, criterion, device):
epoch_loss = 0.0
epoch_acc_1 = 0.0
epoch_acc_5 = 0.0
model.eval()
for (x, y) in iterator:
x = x.to(device)
y = y.to(device)
y_pred = model(x)
loss = criterion(y_pred, y)
acc_1, acc_5 = calculate_topk_accuracy(y_pred, y, k=2)
epoch_loss += loss.item()
epoch_acc_1 += acc_1.item()
epoch_acc_5 += acc_5.item()
epoch_loss = epoch_loss / len(iterator)
epoch_acc_1 = epoch_acc_1 / len(iterator)
epoch_acc_5 = epoch_acc_5 / len(iterator)
return epoch_loss, epoch_acc_1, epoch_acc_5
8) 모델 Train, Validation
best_valid_loss = float('inf')
EPOCHS = 10
for epoch in range(EPOCHS):
start_time = time.monotonic()
train_loss, train_acc_1, train_acc_5 = train(model, train_iterator, optimizer, criterion, device)
valid_loss, valid_acc_1, valid_acc_5 = evaluate(model, val_iterator, criterion, device)
if valid_loss < best_valid_loss :
best_valid_loss = valid_loss
torch.save(model.state_dict(), '../data/ResNet-model.pt')
end_time = time.monotonic()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc @1: {train_acc_1*100:6.2f}% | ' \
f'Train Acc @5: {train_acc_5*100:6.2f}%')
print(f'\tValid Loss: {valid_loss:.3f} | Valid Acc @1: {valid_acc_1*100:6.2f}% | ' \
f'Valid Acc @5: {valid_acc_5*100:6.2f}%')참고자료
https://chickencat-jjanga.tistory.com/141
'DL > CNN' 카테고리의 다른 글
| [DL][CNN] GoogLeNet 개념 및 Pytorch 구현 (0) | 2025.03.29 |
|---|---|
| [DL][CNN] VGGNet 개념 및 Pytorch 구현 (1) | 2025.02.27 |
| [DL][CNN] AlexNet 개념 및 Pytorch 구현 (0) | 2025.02.21 |
| [DL][CNN] LeNet-5 (1) | 2025.01.15 |
| [DL][CNN] 설명 가능한 AI (Explainable Artificial Intelligence, XAI)와 Feature Map 시각화, PyTorch 예제 (1) | 2025.01.15 |



