1. AlexNet 이란?
ImageNet 영상 데이터베이스를 기반으로 한 화상인식대회인 "ILSVRC(ImageNet Large Scale Visural Recognition Challenge) 2012"에서 우승한 CNN 구조이다.
Convolution Layer 5개와 Fully Connected Layer 3개로 구성되어 있으며, 마지막 Fully Connected Layer는 카테고리 1000개를 분류하기 위해 Softmax 활성화 함수를 사용했다.
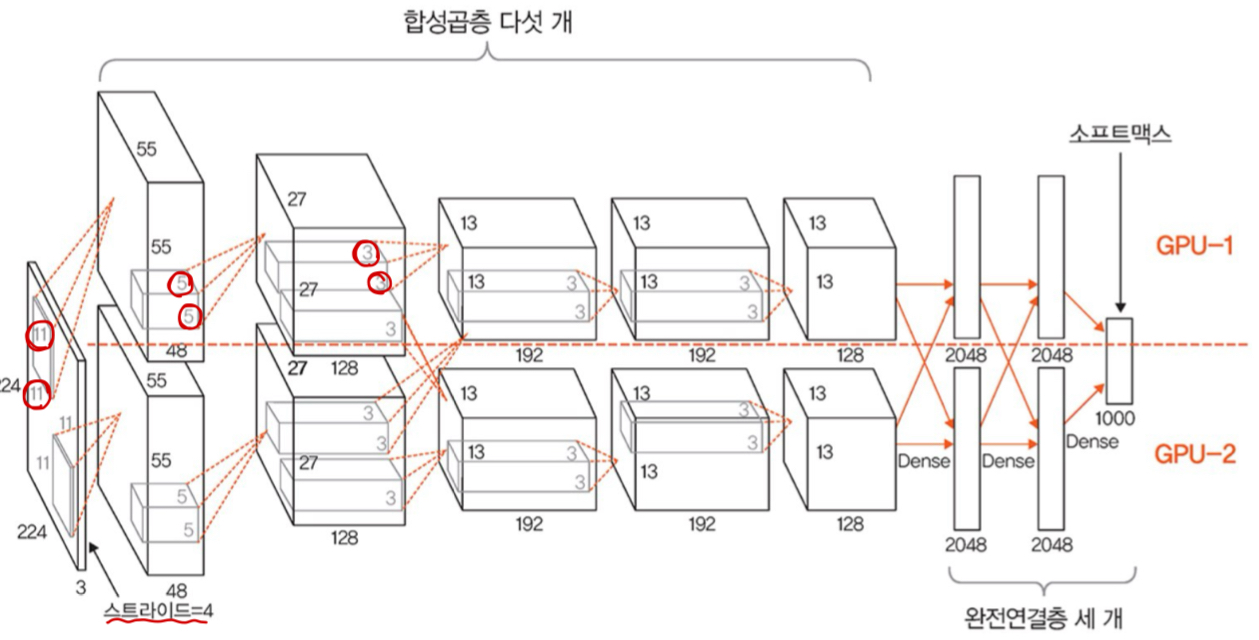
전체적으로 보면 GPU 두개를 기반으로 한 병렬 구조인 점을 제외하면 LeNet-5와 크게 다른 점이 없다.
2. AlexNet의 구조
- Input : 224 x 224 x 3 크기의 Image
- Convolution Layer 1 : 11 x 11 크기의 96개 Filter(out_channel=96)에 stride 4와 padding 2를 적용하여 Feature Map 추출 (연산 후 Feature Map 크기 : 55 x 55 x 96)
- ReLU Activation Function
- Max Pooling : 3 x 3 크기의 Filter를 stride 2를 적용하여 Feature Map 크기 축소 (연산 후 Feature Map 크기 : 27 x 27 x 96)
- Convolution Layer 2 : 5 x 5 크기의 256개 Filter(out_channel=256)에 stride 1과 padding 2를 적용하여 Feature Map 추출 (연산 후 Feature Map 크기 : 27 x 27 x 256)
- Max Pooling : 3 x 3 크기의 Filter를 stride 2를 적용하여 Feature Map 크기 축소 (연산 후 Feature Map 크기 : 13 x 13 x 256)
- Convolution Layer 3 : 3 x 3 크기의 384개 Filter(out_channel=384)에 stride 1과 padding 2를 적용하여 Feature Map 추출 (연산 후 Feature Map 크기 : 13 x 13 x 256)
- Convolution Layer 4 :3 x 3 크기의 384개 Filter(out_channel=384)에 stride 1과 padding 2를 적용하여 Feature Map 추출 (연산 후 Feature Map 크기 : 13 x 13 x 256)
- Convolution Layer 5 : 11 x 11 크기의 256개 Filter(out_channel=256)에 stride 1과 padding 2를 적용하여 Feature Map 추출 (연산 후 Feature Map 크기 : 13 x 13 x 256)
- Max Pooling : 3 x 3 크기의 Filter를 stride 2를 적용하여 Feature Map 크기 축소 (연산 후 Feature Map 크기 : 6 x 6 x 256)
- Fully Connected Layer 1 : 6×6×256(=4096)개 뉴런을 입력으로 받아, Dropout 0.5를 적용한 후 4096개 뉴런으로 변환하고 ReLU 활성화 함수를 사용
- Fully Connected Layer 2 : 4096개 뉴런을 입력으로 받아, Dropout 0.5를 적용한 후 4096개 뉴런으로 변환하고 ReLU 활성화 함수를 사용
- Fully Connected Layer 3(Output layer) : 4096개 뉴런을 입력으로 받아 1000개 뉴런으로 변환하여 최종 출력층을 구성
※ Convolution Layer와 MaxPooling 후 Feature Map 크기 변화 공식
- Convolution Layer(in_channel = $C_1$, out_channel=$C_2$
- Input = $W_1$ x $H_2$ x $C_1$, Kernel Size = F, Stride = S, Padding = P
- $W_2 = \frac{W_1 - F + 2P}{S} + 1$
- $H_2 = \frac{H_1 - F + 2P}{S} + 1$
- Output Feature Map = $W_2$ x $H_2$ x $C_2$
-
- Input = $W_1$ x $H_2$ x $C_1$, Kernel Size = F, Stride = S, Padding = P
- $W_2 = \frac{W_1 - F}{S} + 1$
- $H_2 = \frac{H_1 - F}{S} + 1$
- $C_2 = C_1$ Max Pooling
3. AlexNet PyTorch 구현
1) 라이브러리 호출
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2) Image 데이터 전처리 방법 정의
# AlexNet을 구현하기 위해 Image 크기를 224x224로 Resize
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])3) CIFAR-10 데이터 셋 불러오기
# CIFAR-10 데이터 로드
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)4) AlexNet Model 정의
class AlexNet(nn.Module):
def __init__(self, num_classes=10): # CIFAR-10은 클래스가 10개
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x6) Model, Optimizer, Loss Function 정의
model = AlexNet(num_classes=10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)7) Model Train 및 Model 평가
num_epochs = 5
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}")
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Test Accuracy: {100 * correct / total:.2f}%")'DL > CNN' 카테고리의 다른 글
| [DL][CNN] GoogLeNet 개념 및 Pytorch 구현 (0) | 2025.03.29 |
|---|---|
| [DL][CNN] VGGNet 개념 및 Pytorch 구현 (1) | 2025.02.27 |
| [DL][CNN] LeNet-5 (1) | 2025.01.15 |
| [DL][CNN] 설명 가능한 AI (Explainable Artificial Intelligence, XAI)와 Feature Map 시각화, PyTorch 예제 (1) | 2025.01.15 |
| [DL][CNN]전이학습의 미세조정 기법(Fine - Tuning) 개념 및 PyTorch 예제 (0) | 2025.01.14 |



