1. VGGNet이란?
VGGNet은 2014년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 처음 발표된 CNN 모델로, 네트워크의 깊이가 성능에 미치는 영향을 분석하기 위해 설계되었다.
기존 모델보다 깊은 구조를 가지면서도 설계를 단순화하기 위해 합성곱 층의 Kernel 크기를 모두 3 × 3으로 고정하여 작은 커널을 여러 번 쌓아 깊은 네트워크를 구성할 수 있게 되어 불필요한 복잡성을 줄였다.
또한, 합성곱층 사이에 2×2 크기의 Max Pooling을 적용하여 특성 맵의 크기를 효율적으로 줄이면서도 중요한 정보를 유지할 수 있도록 설계되었다.
이러한 구조적 특징 덕분에 VGGNet은 비교적 간결한 설계 방식으로도 깊은 네트워크를 구성할 수 있었으며, 이후 등장한 ResNet, DenseNet과 같은 심층 신경망 모델의 발전에 중요한 영향을 미쳤다.
VGGNet의 대표적인 변형 모델로는 VGG16(16개 가중치 층)과 VGG19(19개 가중치 층)이 있으며, 주로 이미지 분류 및 전이 학습(Transfer Learning)에서 널리 사용된다. 하지만 깊은 구조로 인해 연산량이 많고, 메모리 사용량이 크다는 단점이 있어 최신 모델 대비 효율성이 떨어지는 부분이 있다.
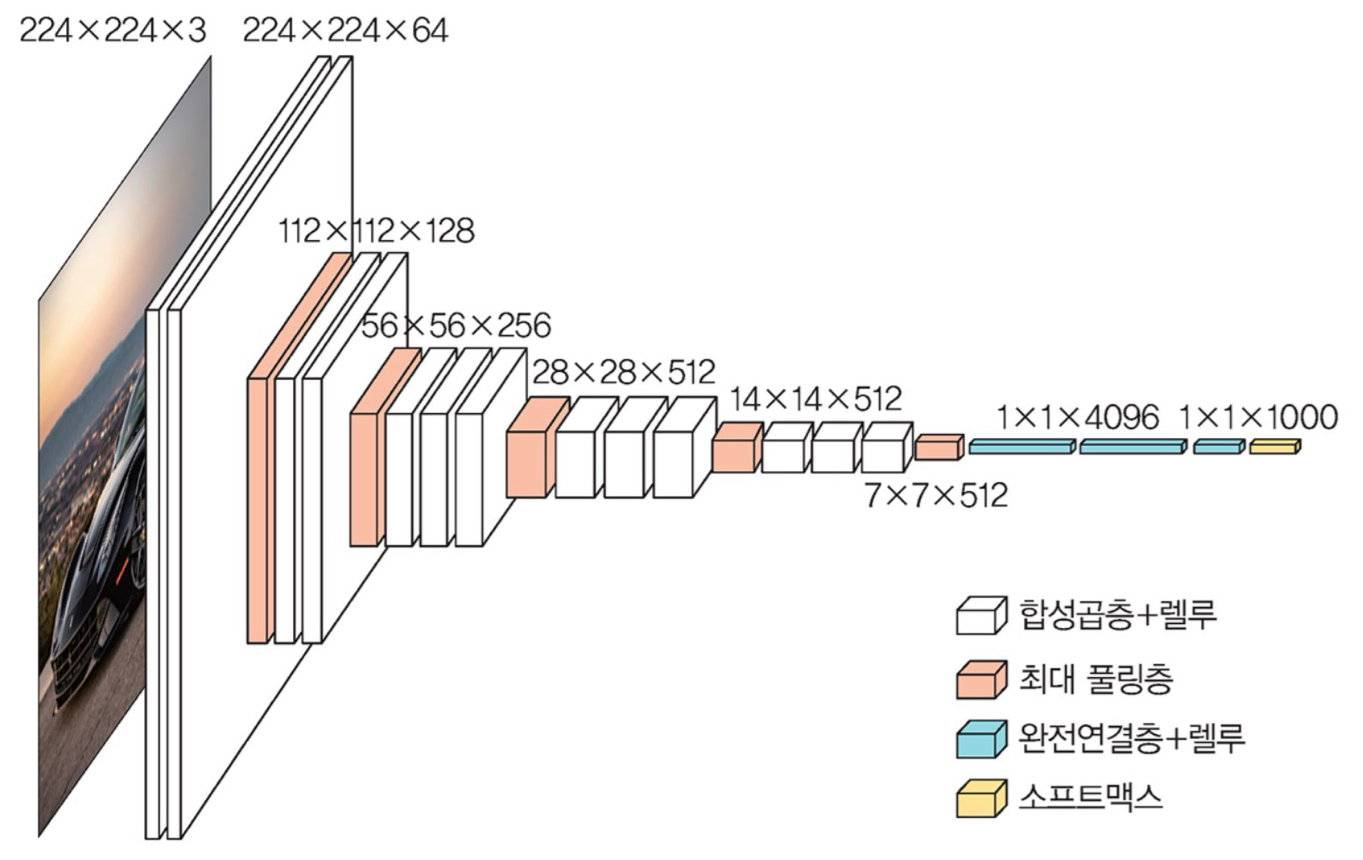
위 그림은 VGG16을 나타낸 그림입니다.
2. VGGNet의 구조
VGG16을 기반으로 구조를 설명드리겠습니다.(VGG16 = 13개의 합성곱층 + 3개의 완전연결층)
- Input : 224 x 224 x 3 크기의 Image
- Conv(3, 64, kernel_size=(3,3)) -> Conv(64, 64, kernel_size=(3,3)) -> MaxPooling(2,2)
- Conv(64, 128, kernel_size=(3,3)) -> Conv(128, 128, kernel_size=(3,3)) -> MaxPooling(2,2)
- Conv(128, 256, kernel_size=(3,3)) -> Conv(256, 256, kernel_size=(3,3)) -> Conv(256, 256, kernel_size=(3,3)) -> MaxPooling(2,2)
- Conv(256, 512, kernel_size=(3,3)) -> Conv(512, 512, kernel_size=(3,3)) -> Conv(512, 512, kernel_size=(3,3)) -> MaxPooling(2,2)
- Conv(256, 512, kernel_size=(3,3)) -> Conv(512, 512, kernel_size=(3,3)) -> Conv(512, 512, kernel_size=(3,3)) -> MaxPooling(2,2)
- FC(7*7*512, 4096) -> FC(4096, 4096) -> FC(4096, num_classes)
3. AlexNet PyTorch 구현
1) 라이브러리 호출
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")2) Image 데이터 전처리 방법 정의
# VGGNet 구현하기 위해 Image 크기를 224x224로 Resize
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])3) CIFAR-10 데이터 셋 불러오기
# CIFAR-10 데이터 로드
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)4) VGGNet Model 정의
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Linear(7*7*512, 4096), nn.ReLU(inplace=True),
nn.Linear(4096, 4096), nn.ReLU(inplace=True),
nn.Linear(4096, 10)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x6) Model, Optimizer, Loss Function 정의
model = VGG16().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)7) Model Train 및 Model 평가
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss / len(train_loader):.4f}")
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")'DL > CNN' 카테고리의 다른 글
| [DL][CNN] ResNet 개념 및 Pytorch 구현 (0) | 2025.04.30 |
|---|---|
| [DL][CNN] GoogLeNet 개념 및 Pytorch 구현 (0) | 2025.03.29 |
| [DL][CNN] AlexNet 개념 및 Pytorch 구현 (0) | 2025.02.21 |
| [DL][CNN] LeNet-5 (1) | 2025.01.15 |
| [DL][CNN] 설명 가능한 AI (Explainable Artificial Intelligence, XAI)와 Feature Map 시각화, PyTorch 예제 (1) | 2025.01.15 |



