최대 우도 추정법(Maximum Likelihood Estimation, MLE)
최대 우도 추정법(Maximum Likelihood Estimation, MLE)는 확률변수에서 추출한 표본 값(관측 데이터)들을 토대로 우도(Likelihood)를 최대화하는 방향으로 확률변수의 모수(파라미터)를 추정한다
이 때 Likelihood를 최대화하는 parameter는 얻은 샘플로부터 모집단의 분포를 추정하였을 때 가장 적합한 parameter이다
그럼 여기서 우도(Likelihood)란 무엇인가?
우도 확률(Likelihood Probability, $P(X | w)$)
- 모델 파라미터(모수) 값을 잘 모르지만 안다고 가정했을 때, 주어진 데이터의 분포
- 따라서, 모델 파라미터(w)에 대한 함수로 데이터의 분포를 표현
- 각 샘플이 i.i.d(independent and identical distributed)하다고 가정 후, PDF(Probabilty Density Function, 확률 밀도함수)의 곱으로 표현
ex) 정규분포를 따르는 데이터에 대한 우도 확률
$w = \mu(평균), \sigma(분산)$
$PDF : \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2} (\frac{x - \mu}{\sigma})^2}$
$Likelihood = \prod_i \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2} (\frac{x_i - \mu}{\sigma})^2}$
$L(w | X) = P(X|w) = \prod_i P(x_k | w)$
※ 확률(Probability) vs 우도(Likelihood)
- 확률 : 관측값이 확률 분포 안에서 얼마의 확률로 존재하는가를 나타내는 값
- 우도 : 특정한 값을 관측했을 떄, 이 관측치가 어떠한 확률분포에서 나왔는가 에 관한 값
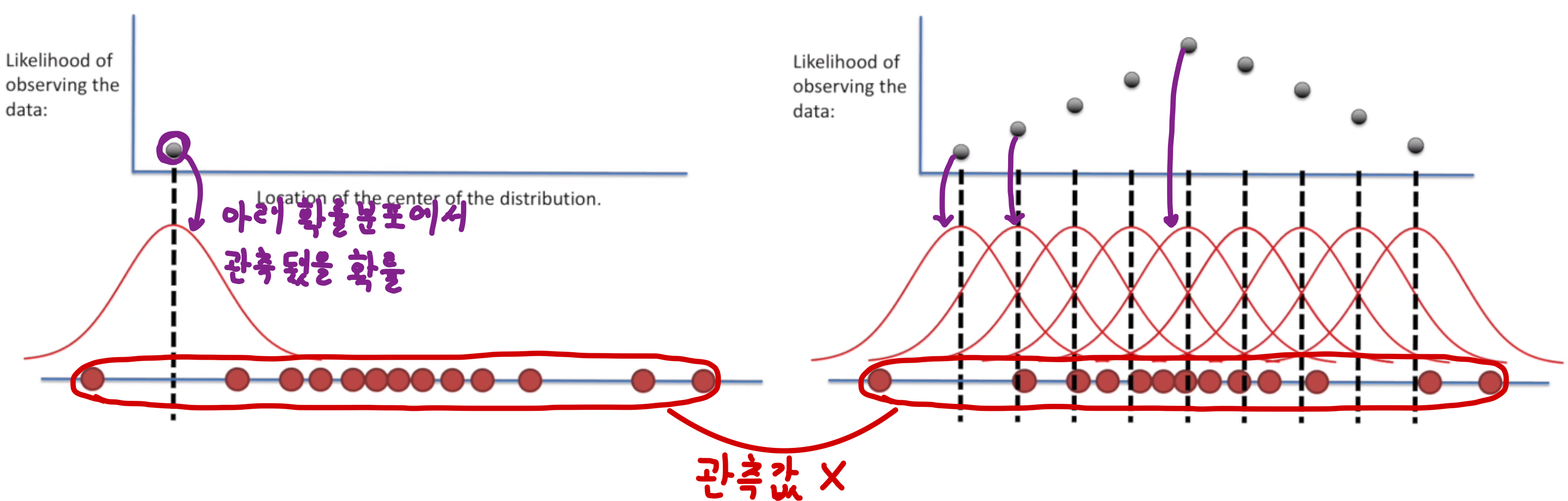
이제 다시 MLE 설명으로 돌아오겠습니다 !
최대 우도 추정법(Maximum Likelihood Estimation, MLE)는 확률변수에서 추출한 표본 값(관측 데이터)들을 토대로 우도(Likelihood)를 최대화하는 방향으로 확률변수의 모수(파라미터)를 추정한다
- 즉, 현재의 데이터 분포가 가장 나올 확률이 가장 높은 파라미터를 추정한다
- $\hat{w} = \underset{c}{\arg\max} P(X | w)$
- 매운 간단해 보이는 파라미터 추정법이지만, 데이터에 따라 값이 민감하게 변화한다(즉, 데이터가 많을수록 좋다)
ex) 정규분포에서 독립추출한 표본
$X = {x_1, x_2, \cdots, x_n}$
\begin{align}
&f_{\mu, \sigma^2} (x_k) = \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2} (\frac{x_k - \mu}{\sigma})^2}\\
&L(w | X) = P(X | w) = \prod_i P(x_k | w) = \prod_i \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2} (\frac{x_i - \mu}{\sigma})^2}\\
&\log{(L(w | X))} = \sum_i \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2} (\frac{x_i - \mu}{\sigma})^2} = \sum_i {-\frac{(x_k -\mu)^2}{ 2 \sigma^2} - \log(\sigma \sqrt{2 \pi})}
\end{align}
여기서 $ \log{(L(w | X))}$를 최대화하는 모수($\mu, \sigma$)를 추정해야한다
- $\frac{\partial L}{\partial \mu} = 0 = \sum_i {x_k - \mu}{\sigma^2}$ ==> $\hat{\mu} = \frac{1}{n} \sum_i x_k$
- $\frac{\partial L}{\partial \sigma} = 0 = \sum_i -\frac{(x_k -mu)^2}{ \sigma^2 } - \frac{1}{\sigma}$ ==> $\hat{\sigma}^2 = \frac{1}{n} \sum_i (x_k-\mu)^2$
위의 결과를 보면 모평균, 모분산과 같다
'ML' 카테고리의 다른 글
| [ML]라그랑주 승수법(Lagrange Multiplier Method) (3) | 2024.06.17 |
|---|---|
| [ML] 이동평균(Moving Average, SMA, CMA, WMA, EMA) (1) | 2024.06.10 |
| [ML] 최대 사후 확률(Maximum A Posterior, MAP) (0) | 2024.06.07 |
| [ML]OverFitting 해결방법(Validation, Regularization) (0) | 2024.06.04 |
| [ML]Bias and Variance Trade-Off(분산 편향 트레이드 오프) (1) | 2024.05.29 |

