※ Notation
$f(x)$ : Input x에 대한 실제 정답, 하나 존재
$\hat{f(x)}$ : Input x에 대한 Model의 예측값, 다양한 값 존재
$E[\hat{f(x)}]$ : $ \hat{f}(x) $에 대한 기댓값
모델 복잡도(Model Complexity)
- 모델의 파라미터 수가 많아질수록(선형 모델 -> 비선형 모델), 모델 복잡도가 증가
- 모델이 복잡해질수록 학습 데이터를 더욱 완벽하게 학습
- 학습 데이터가 많은 경우 : Under-fitting
- 학습 데이터가 적은 경우 : Over-fitting
Bias vs Variance
편향과 분산은 알고리즘이 가지고 있는 에러의 종류이다.
Bias(편향)
- Model을 통해 얻은 예측값과 실제 정답과의 차이
- 즉, 예측값이 실제 정답과 얼마만큼 떨어져있는지를 나타낸다
- $Bias[\hat{f}(x)] = E[\hat{f}(x) - f(x)]$
추정 결과가 한 쪽으로 치우치는 경향을 보임으로써 발생하는 error
지나치게 단순한 모델로 인한 error, 편향이 크면 Under Fittitng을 야기한다.
Variance(분산)
- 다양한 데이터 셋에 대해 예측값이 얼마만큼 변할 수 있는지에 대한 양(Quantity)의 개념
- 모델이 얼만큼 Flexibility를 가지는지에 대한 의미로도 사용되며, 분산의 원래 의미처럼 예측값이 얼만큼 퍼져 다양하게 출력될 수 있는 정도로 해석가능하다
- $Var[ \hat{f}(x) ] = E[( \hat{f}(x) - E[ \hat{f}(x) ])^2] = E[ \hat{f}(x) ^2] - E[ \hat{f}(x) ]^2 $
변량들이 퍼져있는 정도를 의미
지나치게 복잡한 모델로 인한 error, 분산이 크면 Over-fittitng을 야기한다.

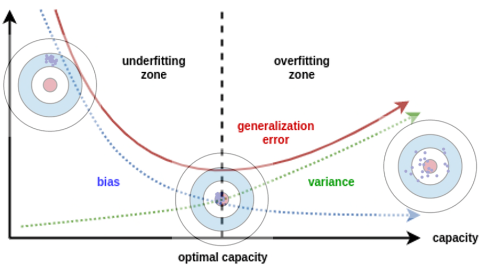
왼쪽 그림 - 낮은 복잡도의 모델 : 편향이 높고 분산이 작다
오른쪽 그림 - 높은 복잡도의 모델 : 편향이 낮고 분산이 크다
ML 모델과 Bias 및 Variance의 관계
$$
\begin{align}
Error[\hat{\theta}] &= E_{\theta}\big[ (\hat{\theta} - \theta)^2\big] = E\big[ \{ \hat{\theta} - E[\hat{\theta}] + E[\hat{\theta}] -\theta\}^2\big] \\
&= E\Big[ \{ \hat{\theta} - E[\hat{\theta}]\}^2 + 2 \{(\hat{\theta} - E[\hat{\theta}]) (E[\hat{\theta}] - \theta)\} + \{E[\hat{\theta}] - \theta\}^2 \Big] \\
&= E\Big[ \{ \hat{\theta} - E[\hat{\theta}]\}^2\Big] + 2\{ E[\hat{\theta}] - \theta\} E[\hat{\theta} - E[\hat{\theta}]] + \{E[\hat{\theta}] - \theta\}^2 \\
&= E\Big[ \{ \hat{\theta} - E[\hat{\theta}]\}^2\Big] + \{E[\hat{\theta}] - \theta\}^2 \\
&= Var_{\theta}(\hat{\theta}) + Bias_{\theta}(\hat{\theta}, \theta)^2
\end{align}
$$
위에서 설명했던 것처럼 Bias와 Variance는 모델 복잡도와 관련이 있다.
또한, 서로에게도 영향이 있다
Bias를 낮추기 위해(Under-fitting 해결) 모델 복잡도를 올리면 Variance 가 증가한다.
Variance를 낮추기 위해(Over-fitting 해결) 모델 복잡도를 낮추면 Bias가 증가한다.
이렇게 때문에 Bias와 Variance 간 Trade - Off가 있다고 얘기한다.
따라서 적당한 수준의 bias와 variance 를 만들기 위해 적정 수준에서 학습을 종료한다
'ML' 카테고리의 다른 글
| [ML]라그랑주 승수법(Lagrange Multiplier Method) (3) | 2024.06.17 |
|---|---|
| [ML] 이동평균(Moving Average, SMA, CMA, WMA, EMA) (1) | 2024.06.10 |
| [ML] 최대 사후 확률(Maximum A Posterior, MAP) (0) | 2024.06.07 |
| [ML] 최대 우도 추정법(Maximum Likelihood Estimation, MLE) (2) | 2024.06.07 |
| [ML]Over Fitting 해결방법(Validation, Regularization) (0) | 2024.06.04 |

