※ Remind
회귀(Regression)
- Input : 연속형(실수값), 이산형(범주형) 모두 가능
- Output : 연속형(실수형)
분류(Classification)
- Input : 연속형(실수값), 이산형(범주형) 모두 가능
- Output : 이산값(범주형)
- Binary Classification이라면 시그모이드 함수, Multiclass Classification이라면 소프트맥수 함수 사용
※ Notation
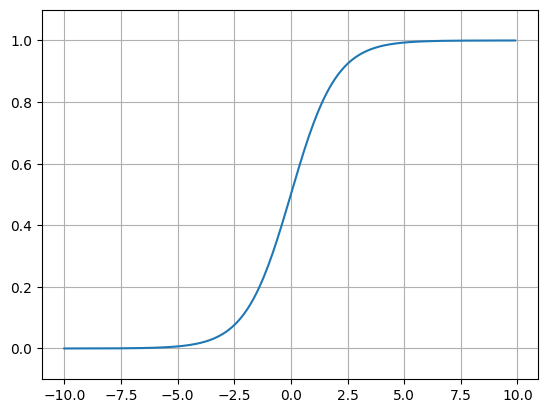
시그모이드(Sigmoid) 함수
S자형 곡선 또는 시그모이드 곡선을 갖는 함수
Binary Classification, Deep Learning에서 Activation Function으로 사용
$$y = \frac{1}{1 + e^{-x}} = \frac{e^x}{1 + e^x }$$
소프트맥스(Softmax) 함수
Multiclass Classification, Deep Learning에서 출력층에서 사용
$$ y_i = \frac{e^{x_i}} {\sum \limits_{k=1}^{K} e^{x_k}} \quad for \; i = 1 , ... , K$$
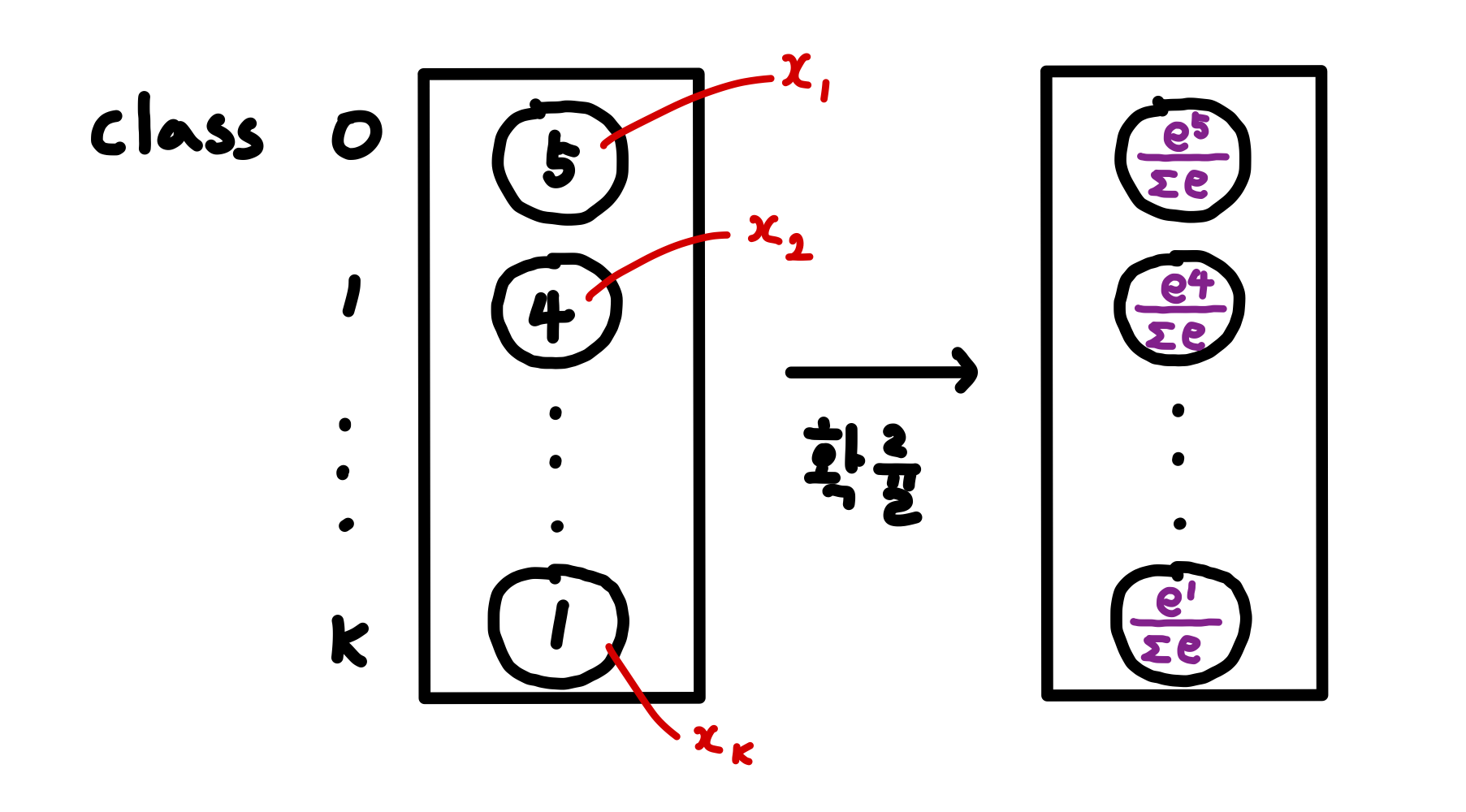
여기서 K는 클래스의 개수
로지스틱 회귀를 보기 앞서 여러가지를 설명하고 시작하겠습니다 !
Odds(오즈)
오즈비라고도 하며 성공(y=1) 확률이 실패(y=0) 확률에 몇 배 더 높은가 를 나타냅니다
$$Odds = \frac{p(y=1 | x)}{1 - p(y=1 | x)}$$
Logit Transformtaion(로짓 변환)
Odds에 로그를 취한 함수 형태
입력값(Odds, p)의 범위가 [0, 1]일 때 [$-\infty, \infty$] 를 출력
$$Logit(p) = log(odds) = \log\big(\frac{p(y=1 | x)}{1 - p(y=1 | x)}\big)$$
Logistic Function(로지스틱 함수)
Logit Transformation의 역함수로 해석가능
$$Logit(p) = log(odds) = \log\big(\frac{p(y=1 | x)}{1 - p(y=1 | x)}\big) = w_0 + w_1 x_1 + \cdots + w_D x_D = w_0 + w^T X$$
이때 $p(y=1 | x)$는 아래와 같습니다
$$p(y=1|x) = \frac{e^{w_0 + w^T X}}{1 + e^{w_0 + w^T X}} = \frac{1}{1 + e^{-(w_0+ w^T X)}}$$
즉, Logistic Function은 Linear Regression(선형 회귀)와 Sigmoid(시그모이드) 함수의 결합입니다
다시 한번 수식으로 설명하자면 아래와 같습니다
\begin{aligned}
&f(p) = logit(p) = \log\big(\frac{p}{1 - p}\big) = w_0 + w^T X = y\\
&p = f^{-1}(w_0 + w^T X) = \frac{1}{1 + e^{-(w_0 + w^T X)}}
\end{aligned}
이제까지 로지스틱 회귀를 배우기 전 기본적인 개념을 알아보았고
이제부터 로지스틱 회귀에 대해 설명 시작하겠습니다 !
Logistic Regression(로지스틱 회귀)
로지스틱 회귀란?
일반적인 회귀 분석과 동일하게 종속변수($y$)와 독립 변수($x$)간의 관계를 나타내어 향후 예측 모델에 사용됩니다
선형 회귀 분석과 유사하게 독립 변수의 선형 결합으로 종속 변수를 설명하게 됩니다
위에서 봤던 것처럼 독립 변수의 선형 결합($w_0 + w_1 x_1 + \cdots + w_D x_D$)을 Sigmoid 함수랑 결합한 로지스틱 함수 형태의 회귀 모델이비낟
$ p(\hat{y} =1 | X) = \frac{1}{1 + e^{-(w_0 + w^T X)}} $ 의 값이 0.5보다 크면 1로 분류, 0.5보다 작으면 0으로 분류합니다
여기서 paramter w의 최적값을 찾아야하는데 이를 위한 Loss Function은 어떻게 정의할 것인가??
※ Bayes' Theorem(베이즈 정리)
베이즈 정리란 두 확률 변수의 사전 확률(Prior Probability)과 사후 확률(Posterior Probability) 사이의 관계를 나타내는 정리입니다
베이즈 정리에 따르면 사전확률로부터 사후확률을 구할 수 있습니다
- 사후확률(Posterior Probabilty, $P(w | X)$) : 데이터(X)가 주어졌을 떄 가설(w, 모델 파라미터)에 대한 확률 분포
- 우도확률(Liklihood, $P(X | w)$) : 가설을 잘 모르지만 안다고 가정했을 경우, 주어진 데이터의 분포
- 사전확률(Prior Probability, $P(w)$) : 데이터를 보기 전, 일반적으로 알고 있는 가설의 확률
- 증거(Evidence, $P(X)$)
베이즈 정리는 아래 식과 같습니다
$$P(w | X) = \frac{P(w, X)}{P(X)} = \frac{P(X | w)P(w)}{P(x)} \propto P(X | w) P(w)$$
베이즈 정리를 이용하여 사전 확률을 통해 사후 확률을 구한다는게 이해가 어렵습니다
하지만 아래 그림과 식 전개과정을 보며 이해가 가능했으면 좋겠습니다 !
전체 확률의 법칙

\begin{aligned}
P(X) &= P(X \cap w)\\
&= P(X \cap w_1) + P(X \cap w_2) \\
&= P(w_1) \cdot P(X | w_1) + P(w_2) \cdot P(X | w_2)
\end{aligned}
전체 확률의 법칙을 통해 사후 확률(Posterior Probability) 구하기
$$ P(w | X) = \frac{P(X | w) \cdot P(w)}{P(X)} = \frac{P(X | w) \cdot P(w)} {\sum \limits_{i=1}^{n} P(w_i) \cdot P(X | w_i)}$$
여기서 우도확률($P(X|w)$)과 사전확률($P(w)$)은 어떻게 하나라는 생각이 들텔데
우도확률은 주어진 데이터의 분포이고, 사전확률은 일반적으로 알고 있는 가설의 확률이라 주어진다고 생각하면 됩니다
이 확률들을 통해 가설을 추정하는 방법으로 MLE(Maximum Likelihood Estimation, 최대 우도 추정), MAP(Maximum A Posterior, 최대 사후 확률)이 있습니다
[ML] 최대 우도 추정법(Maximum Likelihood Estimation, MLE)
최대 우도 추정법(Maximum Likelihood Estimation, MLE)최대 우도 추정법(Maximum Likelihood Estimation, MLE)는 확률변수에서 추출한 표본 값(관측 데이터)들을 토대로 우도(Likelihood)를 최대화하는 방향으로
self-objectification.tistory.com
[ML] 최대 사후 확률(Maximum A Posterior, MAP)
최대 사후 확률(Maximum A Posterior, MAP) [ML] 최대 우도 추정법(Maximum Likelihood Estimation, MLE)최대 우도 추정법(Maximum Likelihood Estimation, MLE)최대 우도 추정법(Maximum Likelihood Estimation, MLE)는 확률변수에
self-objectification.tistory.com
그럼 이제 MLE를 통해 Logistic Regression의 파라미터를 최적화 하는 과정에 대해 알아보자 !
로지스틱 회귀 모델은 로지스틱 함수 형태의 회귀 모델인데 이진 분류로 사용하기 때문에 Parameter p 값이 $ \sigma{(w_0 + w^T X)} $인 베르누이 분포로 해석이 가능합니다
$$P(\hat{y} = 1 | X) = \frac{1}{1 + e^{-(w_0 + w^T X)}} = \sigma{(w_0 + w^T X)}$$
※ 베르누이 분포(Benoulli Distribution)
베르누이 시행 : 두 가지 결과값(실패 : 0, 성공 : 1)만을 가지는 실험을 가정
베르누이 시행에 따라 값을 대응시킨 확률변수를 베르누이 확률변수를 부르고 이 확률변수의 분포를 베르누이 분포라 부릅니다
베르누이의 분포의 Probability Density Function(확률 밀도함수)는 아래와 같습니다
$P(Y = y_i) = p^{y_i} (1-p)^{(1-y_i)} $ (parameter p 는 $y_i = 1$일 확률)
이 때 우도 함수는 PDF의 곱으로 나타내므로 $L(p) = \Pi_i p^{y_i} (1-p)^{(1-y_i)} $ 가 됩니다
따라서, 로지스틱 회귀 모델의 우도함수는 아래 식과 같습니다
$$L = \prod_i \sigma{(w_0 + w^T X)}^{y_i} (1-\sigma{(w_0 + w^T X)})^{1 - y_i} $$
이 때 로그 함수는 단조 증가 함수이므로, L과 $\ln L$을 최대로 하는 parameter는 동일합니다
또한, Log Likelihood function을 최대화하는 것은 - Log Likelihood function을 최소화하는 것과 같으로 $- \ln L$을 Loss Function으로 사용합니다 (왜냐하면 Loss Function을 최소화하는 방향으로 사용했기 때문에 형태를 바꾸어 준 것입니다)
$-\ln L$을 Loss Function으로 하여 Gradient Descent를 적용합니다
Gradient Descent에 대해서 처음 접해보신다면 아래 글을 봐주세요
[Optimization] Gradient Descent(경사하강법)
! Optimization에 대해서 이제 처음 접해보시는 분은 Optimization 정의 먼저 보고 오시면 좋습니다 ! [Optimization] Optimization 정의Optimization(최적화) 란?Optimization이란 최소한의 Cost로 최적의 답을 찾는 과
self-objectification.tistory.com
Loss Function $-\ln L$을 정리하면 아래와 같습니다
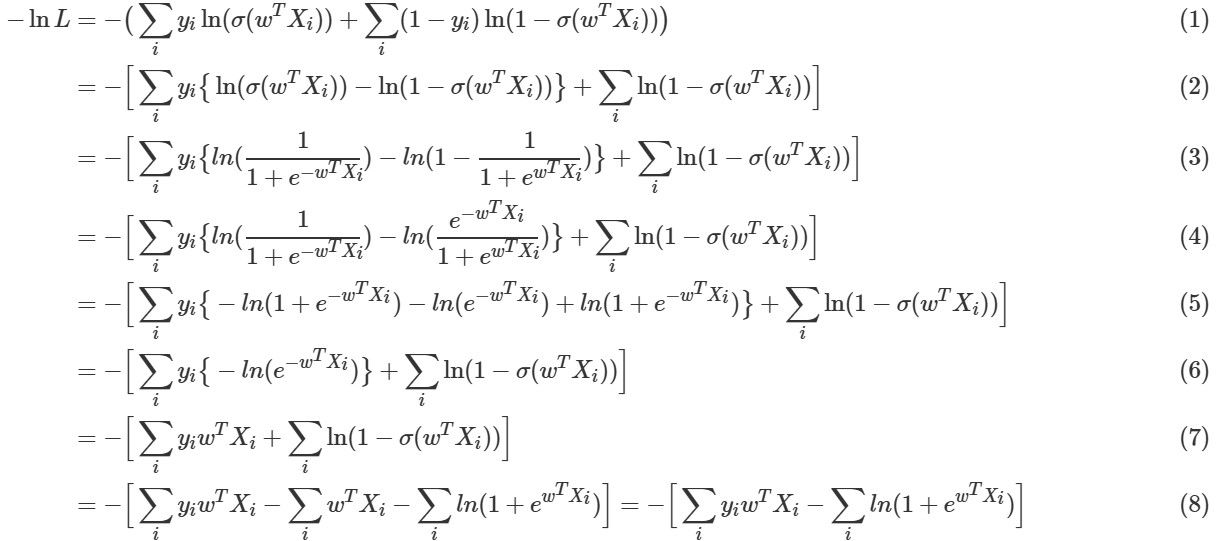
수식(8) 에서 $\sum_i y_i w^T X_i - \sum_i w^T X_i$ 이 $\sum_i y_i w^T X_i$로 정리된 것을 확인할 수 있습니다
여기서 $\sum_i y_i w^T X_i$ 는 $y_i = 1$일 때만 해당되고, $\sum_i w^T X_i$는 모든 $i$에 대해 해당합니다
그러므로 최종 식에서 $\sum_i w^T X_i$는 소거됩니다
즉, 최종 식에서 $\sum_i$는 $y_i=1$인 $X_i$만을 사용하여 계산된다는 것을 의미합니다
이제 정리된 Loss Function에 Gradient Descent를 적용하면 됩니다
$\frac{\partial \ln L}{\partial w} = \{\sum_i y_i X_i\} + \{ \sum_i X_i \cdot \frac{e^{^T X_i}}{1+e^{w^T X_i}}\} = \sum_i X_i (y_i - P(w; y_i = 1 | X_i))$
$w_{t+1} = w_t - \eta \frac{\partial \ln L}{\partial w}$


