이번 글은 메타코드 M의 "Kaggle 데이터를 활용한 개인화 추천시스템 100% 실습 강의 | 우아한 형제들, 현대카드 출신 Data Scientist 현직자 강의 " 강의에 대한 후기를 작성해보려고 합니다 !
이 강의는 Python의 Numpy, Pandas, Matplotlib, Seaborn, Scikit-learn, Keras에 대해 선행지식을 가지고 있어야 하니 관심 있으신 분들은 따로 공부하시거나 메타코드에 다양한 강의가 있으니 먼저 수강하시는 것을 추천드립니다.
1. 강의 수강 계기
메타코드 M을 알게된 것은 2년전 쯤 우연히 유튜브 강의를 통해서 알게 되었고, 그 강의는 "머신러닝 강의 1,2,3강 - [국내 Top AI대학원 박사] " 였고, 유튜브에 장편으로 Machine Learning에 대해 자세히 설명해주어서 되게 도움이 많이 되었습니다.
그래서 메타코드 M이 운영하는 IT 뉴스 & 채용정보 단톡방에 참여하고 있었는데 이번 추천 시스템 강의의 장학생을 모집한다는 소식을 보고 배민에서 Data scientist로 재직하셨던 강사님이라 도움이 많이 될 것이라 생각하여 바로 신청을 하게 되었습니다.
2. 강의 목차
일단 강의 이름과 목차를 봤을 때 추천 시스템의 이론을 배운다기 보단 추천 시스템을 어떻게 적용할 것 인지에 대한 과정을 한 강의에 담은 것 같았습니다.
즉, 추천 시스템을 접해본 사람이 직접 구현하는 것을 연습하기 위한 강의로는 제격이다 생각했습니다.

강의는 1강에 3~4개의 동영상이 있으면 하나의 동영상 길이는 약 20분정도 됩니다.
3. 강의 내용(현재까지)
현재 4강까지 수강을 완료하여 4강까지의 내용에 대해 작성하겠습니다.
1강 데이터 소개 및 실습 준비
1강은 본 강의에서 사용할 데이터에 대한 EDA를 진행하였습니다.
사용 데이터는 Kaggle에서 제공하는 Book Recommendation Dataset 을 강사님이 한번 더 처리한 데이터를 사용하였습니다.
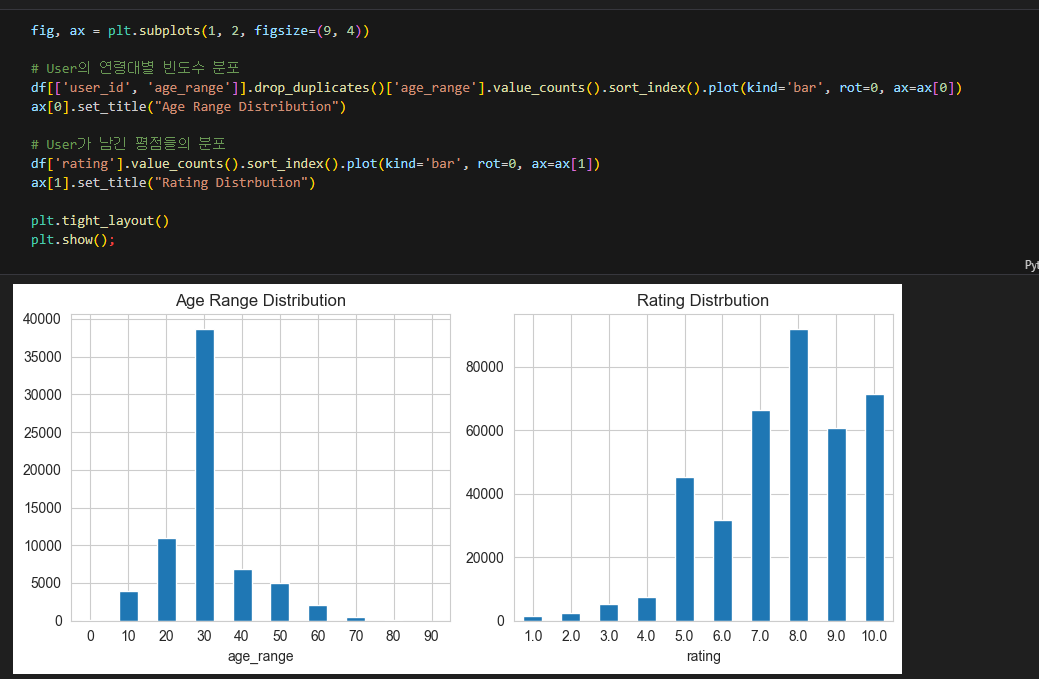
1강에서는 Data의 EDA 방법이나 시각화 방법을 통해 이후 추천 시스템에 적용할 Dataset에 대한 처리방법에 대한 내용입니다. (강의에서는 Kaggle Notebook을 사용하였는데 나는 vscode가 편해서 그냥 vscode를 사용하였습니다.)
2강 추천 시스템 개요
2강에서는 코드를 작성하는 부분을 없고 추천 시스템에 대해 간략하게 보고 넘어가는 강의이다. 이미 추천 시스템에 대해 알고 있다면 다시 한번 들으면서 추천 시스템에 대한 내용을 상기시키고 가면 좋겠습니다.(위에서도 언급했듯이 선행지식이 없다면 이 강의와는 맞지 않다고 생각해서 처음 접하시는 분들은 다른 강의나 추가 공부를 하고 들으시면 좋겠습니다.)
그리고 강의 Markdown에 참고할만한 블로그나 문서를 Link로 달아놀아 주셔서 더 알고 싶은 부분이 있다면 그 Link를 참고하여 공부하였습니다.
3강 베이스라인 추천모델 구축
이제 3강에서부터 본격적으로 Recommendation System의 Collaborative Filtering을 구현해보는 강의이다.
Collaborative Filtering에 대한 설명은 아래 글을 한번 확인해보시면 됩니다.
[Recommendation System] Collaborative Filtering(협업 필터링), Memory - Based Colllaborative Filtering
Collaborative Filtering(협업 필터링)Collaborative Filtering(협업 필터링)이란 많은 사용자로부터 수집한 구매 패턴이나 평점을 기반으로 하여 다른 사용자에게 추천을 하는 방법입니다기본 가정은 "많은
self-objectification.tistory.com
Memory - Based CF(KNN 기반), Model-Based CF(Latent Factor 기반, Matrix Factorization)을 모두 다루기 위해 surprise 라이브러리의 SVD, KNNBasic등의 모델을 사용하여 성능을 비교해보는 것이 강의의 주된 내용입니다.
아래 그림은 강의의 코드를 일부 따온 것인데 이 뿐만 아니라 여러 처리 과정과 다양한 시각화 결과를 알려주십니다 !
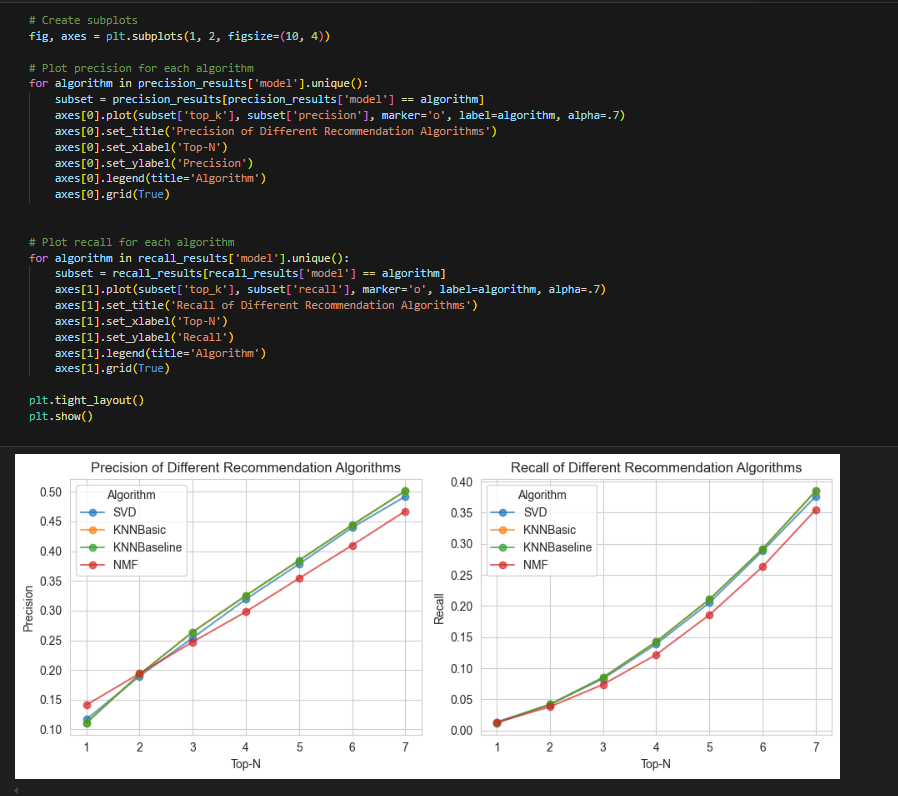
4강 추천알고리즘 성능 고도화
4강에서는 Collarborative Filtering의 베이스라인 모델을 넘어 더 복잡한 알고리즘을 적용하는 강의입니다.
Maching Learnging 에서는 XGBoost, Random Forest, Gradient Boosting 등 Deep Learning 에서는 Deep Neural Network, Neural Collaborative Filtering 모델을 적용하여 이전 Baseline 모델과의 비교, ML 모델과 DL 모델과의 비교를 하는 내용입니다.

위의 그림처럼 다양한 모델에 적용하여 성능을 비교하고 시각화까지 진행하면서 이해가 쉽게 되었습니다.
4. 끝내며
메타코드 M의 "Kaggle 데이터를 활용한 개인화 추천시스템 100% 실습 강의 | 우아한 형제들, 현대카드 출신 Data Scientist 현직자 강의 " 를 장학생에 선정되여 4강까지 수강해보았습니다.
현재까지 추천 시스템의 전체적인 흐름을 따라가는 과정을 배웠다고 생각합니다. EDA, 데이터 전처리, Baseline 모델에 적용하여 빠르게 성능 확인, 모델 성능 고도화 등 현업 Data Scientist 강사님의 짜놓은 Flow를 따라가면서 어떻게 현업에서 진행되는지 느낄 수 있었습니다.(현업에서는 훨씬 더 많은 데이터양과 더 복잡한 모델을 사용하겠지만요..!)
아직 4강까지 밖에 수강하지 못하여 3강이 남은 만큼 열심히 들어서 최종 후기로 다시 돌아오도록 하겠습니다.


