Collaborative Filtering(협업 필터링)
Collaborative Filtering(협업 필터링)이란 많은 사용자로부터 수집한 구매 패턴이나 평점을 기반으로 하여 다른 사용자에게 추천을 하는 방법입니다
기본 가정은 "많은 사용자로부터 얻은 취향 정보를 토대로 나와 비슷한 취향을 가진 사람들이 선호하는 콘텐츠를 나도 좋아할 가능성이 크다"라는 가정을 기반한 Recommendation System입니다
Memory - Based Algorithm(KNN 기반)
User 간 또는 Item 간 Similarity 계산 결과를 기반으로 예측이 필요한 새로운 user와 유사한 취향을 가지고 있는 다른 user가 선호하는 Item을 추천하거나, 특정 Item의 평점을 예측해야 하는 경우 다른 유사한 Tagging이 되어있는 Item의 평점 결과를 토대로 예측
- User - Based Collaborative Filtering(User - User 간의 유사도)
- Item - Based Collaborative Filtering(Item - Item 간의 유사도)
Model - Based Algorithm(Latent Factor 기반)
잠재요인(Latent Factor) Collaborative Filtering은 현재에도 자주 쓰이는 방법으로 User - Item 간 평점 행렬에 숨어 있는 잠재 요인 행렬을 추출하여 행렬 내적 곱을 통해 User가 평가하지 않은 항목들에 대한 평점까지 예측하여 추천하는 방법
Matrix Factorization(행렬 분해)라는 방법을 통해 큰 다차원 행렬을 차원 감소시키는 과정에서 행렬에 포함되어 있는 Latent Factor를 추출할 수 있다
User - Based Collaborative Filtering
유사한 특징을 가지는 User들은 비슷한 취향을 가진다는 것을 가정하여 User의 행동 기록(구매 이력, 평점 등등)을 기반으로 유사한 User들이 선호하는 항목을 추천
예시를 통해 설명하도록 하겠습니다

${\mu}_u$ : User u의 평균 평점
여기서 User - User 간의 Similarity를 구해야합니다
$$Sim(u, v) = pearson(u,v) = \frac{\sum_{K \in I_u \cap I_v} (r_{uk} - \mu_u)(r_{vk} - \mu_v)}{\sqrt{ \sum_{K \in I_u \cap I_v} (r_{uk} - \mu_u)^2} \sqrt{ \sum_{K \in I_u \cap I_v} (r_{vk} - \mu_v)^2 }}$$
계산된 Similarity는 아래 표와 같습니다
| User - ID | 1 | 2 | 3 | 4 | 5 |
| 1 | 0 | 0.7235 | 0.8944 | -0.8992 | -0.8242 |
| 2 | 0.7235 | 0 | 0.9701 | -0.7206 | -0.8992 |
| 3 | 0.8944 | 0.9701 | 0 | -1 | -0.8660 |
| 4 | -0.8992 | -0.7206 | -1 | 0 | 0.8771 |
| 5 | -0.8242 | -0.8992 | -0.8660 | 0.8771 | 0 |
이 때, Pearson 상관계수를 통해 Target User와 유사한 user group(Peer Group)을 형성합니다
(상관계수가 높은 상위 k개의 User 선택)
또한, Weighted Average(가중평균)을 사용하여 Peer Group의 평가를 가중 평균하여 예측 평가를 만들어서 사용합니다
하지만, 문제는 사용자의 평가 척도가 다를 수 있다는 점이 있습니다(어떤 User는 대체로 평점을 높게, 어떤 User는 대체로 평점을 낮게 주는 경향)
따라서, 가중평균을 계산하기 전 각 User의 평가에 Target User의 평균을 빼서 "평가 차이"를 보정할 필요가 있습니다
위에서 설명한 과정을 식으로 나타내면 아래와 같습니다
$$
\hat{r}_{uj} = \mu_u + \frac{\sum_{v \in P_u(j)} Sim(u, v) \cdot s_{vj} }{\sum_{v \in P_u(j)} |Sim(u, v)|} = \mu_u + \frac{\sum_{v \in P_u(j)} Sim(u, v) \cdot (r_{uj} - \mu_u)}{ \sum_{v \in P_u(j)} |Sim(u, v)| }
$$
- $ \hat{r}_{uj} $ : User u가 아직 평가하지 않은 Item j에 대한 예측 평점
- $P_u(j)$ : Peer Group
- $(r_{uj} - \mu_u)$ : Item j에 대한 User u의 Mean - Centered Rating
- $ \frac{\sum_{v \in P_u(j)} Sim(u, v) \cdot (r_{uj} - \mu_u)}{ \sum_{v \in P_u(j)} |Sim(u, v)| } $ : 가중 평균
Item - Based Collaborative Filtering
User - Based Collaborative Filtering은 확장성(Scalability)가 부족하다는 단점이 있다
수백만의 User를 대상으로 유사성을 계산하는 것이 굉장히 부담스럽기 때문이다
따라서 Item - Based CF는 Item에 대한 User들의 Rating을 사용하여 Item - Item 간의 유사도를 기반으로 추천한다
Item - Based CF는 Peer Group 대신 Item을 기반으로 구성한다
따라서 Item 간의 Similarity를 계산하고, 각 User의 평가가 Item을 기준으로 중심화된다
이 때, 각 Item의 Centered 된 평가를 사용하여 Item 간 Adjusted Cosine Similarity를 측정한다

왼쪽 그림은 앞서 사용한 Rating Matrix를 통해 계산한 $s_{uj}$값입니다
$s_{uj} = r_{uj} - \mu_u$ : 각 항목에 대한 Centered Rating
Item - Based Collaborative Filtering은 Adjusted Cosine Similarity를 사용한다고 앞서 설명드렸으니 이를 바탕으로 추천 진행과정을 보도록 하겠습니다
$$
{\large Adjusted\;Cosine(i, j) = \frac{\sum_{K \in U_i \cap U_j} s_{ui} \cdot s_{uj} }{\sqrt{\sum_{u \in U_i \cap U_j} {s_{ui}}^2} \sqrt{ \sum_{u \in U_i \cap U_j} {s_{uj}}^2 }} }
$$
따라서 예측 평점은 아래와 같습니다
$$
\hat{r}_{ut} = \frac{\sum_{j \in Q_t(u)} Adjusted\;Cosine(j, t) \cdot r_{uj}}{ \sum_{j \in Q_t(u)} |Adjusted\;Cosine(j, t)| }
$$
- $Q_t(u)$ : User u가 평가한 Item 중 가장 유사한 Item들의 집합(Similarity가 높은 Top k개)
그럼 User 3에 대한 예시를 보겠습니다
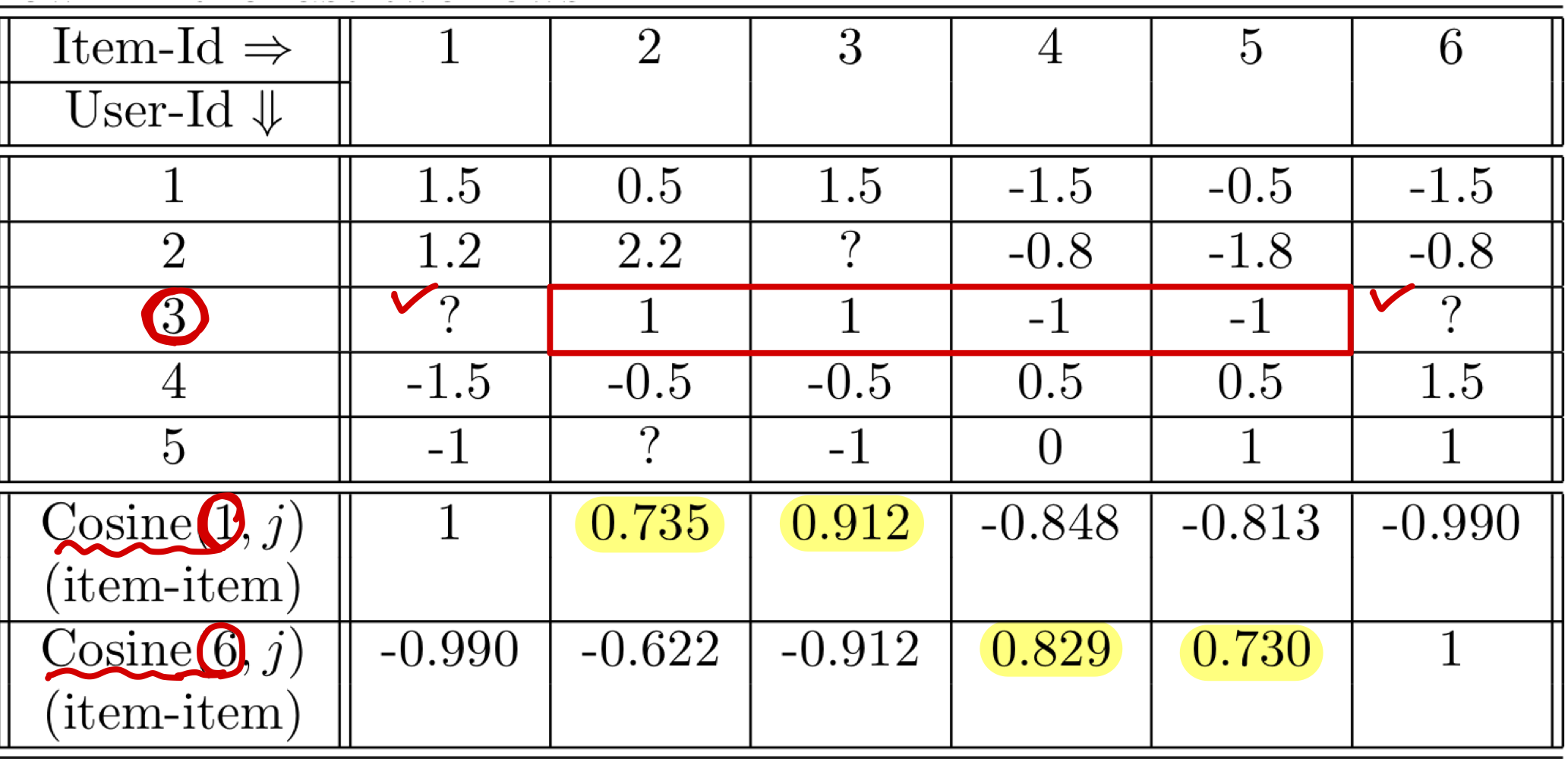
위의 Martix는 앞서 구한 Centered Rating입니다
현재 User 3의 Item 1, 6에 대한 Rating을 모르는 상태라 이를 예측 평점으로 채채워넣어야합니다
아래에 보이는 $Cosine(1, j),\;Cosine(6,j)$를 통해 Item 1과 Similarity가 높은 Top 2 Item은 Item 2,3 이며,
Item 6와 Similarity가 높은 Top 2 Item은 Item 4,5 임을 알 수 있습니다
- Item 1
- $Q_t(u) = \{Item\;2, Item\;3\}$
- $\hat{r}_{31} = \frac{3 \cdot 0.735 + 3}{ 0.735 + 0.912} = 3$
- 따라서 Rating Martix에서 User 3의 Item 1에 대한 Rating은 3으로 예측할 수 있습니다
- Item 6
- $Q_t(u) = \{Item\;4, Item\;5\}$
- $\hat{r}_{31} = \frac{1 \cdot 0.735 + 1 \cdot 0.912}{ 0.735 + 0.912} = 1$
- 따라서 Rating Martix에서 User 3의 Item 6에 대한 Rating은 1으로 예측할 수 있습니다


