1. Encoder의 Self-Attention
Self - Atention의 의미
Attention Function은 주어진 "Query"에 대해서 모든 "Key"와의 유사도를 각각 구하고, 이 유사도를 가중치로 하여 Key와 Mapping 되어 있는 각각의 "Value"에 반영하는 합수이다. 그리고 유사도가 반영된 "Value"를 모두 가중합하여 Attention Value를 구한다.

앞서 Seq2Seq에서 Attention을 사용할 경우 Query, Key, Value는 아래와 같았다.
t 시점이라는 것은 계속 변화하면서 반복적으로 Query를 수행하므로 전체 시점에 대해서도 일반화할 수 있다
- Q : t 시점의 Decoder Cell에서의 hidden State -> 모든 시점의 Decoder Cell에서의 은닉 상태들
- K : 모든 시점의 Encoder Cell의 은닉 상태들 -> 모든 시점의 Encoder Cell의 은닉 상태들
- V : 모든 시점의 Encoder Cell의 은닉 상태들 -> 모든 시점의 Encoder Cell의 은닉 상태들
이처럼 기존에는 Decoder Cell의 Hidden State가 Query이고, Encoder Cell의 Hidden State가 Key라는 점에서 Q와 K가 서로 다른 값을 가지고 있었다.
하지만 Self-Attention에서는 Q, K, V가 전부 동일하다(값이 동일한 것이 아니라 출처가 동일한 것)
- Q : 입력 문장의 모든 단어 벡터들
- K : 입력 문장의 모든 단어 벡터들
- V : 입력 문장의 모든 단어 벡터들
Query, Key, Value 벡터 얻기
Self-Attention은 입력 문장의 모든 단어 벡터들을 가지고 수행된다고 하였는데, 사실 Self-Attention은 Encoder의 초기 입력인 $d_{model}$의 차원(Embedding 차원)을 가지는 단어 벡터들을 사용하여 Self-Attention을 수행하는 것이 아니라, 우선 각 단어 벡터들로부터 Q 벡터, K 벡터, V 벡터를 얻는 작업을 거친다.
이 때, Q 벡터, K 벡터, V 벡터들은 초기 입력인 $d_{model}$의 차원을 가지는 단어보다 더 작은 차원을 가지는데 논문에서는 $d_{model}$=512의 차원을 가졌던 각 단어 벡터들을 64의 차원을 가지는 Q벡터, K벡터, V벡터로 변환하였다.
64라는 값은 Transformer의 $num\_heads$로 인해 결정되는데, Transformer는 $d_{model}$을 $num\_heads$로 나눈 값을 Q, K, V 벡터의 차원으로 결정한다.
아래 그림은 "student"를 통해 단어벡터를 Q, K, V 벡터로 변환하는 과정에 대한 예시이다.

기존의 단어 벡터로부터 더 작은 벡터는 각각의 가중치 행렬($W^Q, W^K, W^V$)과 곱해짐으로서 완성된다 .
각 가중치 행렬은 $d_{model} \times (d_{model}/num\_heads)$의 크기를 가지고, Train 과정에서 학습된다.
모든 단어 벡터에 위와 같은 과정을 거치면 각각의 단어 벡터에 대한 Q, K, V Vector를 얻을 수 있다.
Scaled Dot Product Attention
Q, K, V Vector를 얻었다면 지금부터는 기존의 Attention Mechanism과 동일하다.
각 Q Vector는 모든 K Vector에 대해 Attention Score를 구하고, Attention Distribution을 구한 뒤에 이를 사용하여 모든 V Vector와 가중합하여 Attention Value를 구하게 된다. 이를 모든 Q Vector에 대해 반복한다.
Attention Mechanism에 대한 자세한 내용은 아래 글에 있습니다.
[DL][NLP] Attention Mechanism(어텐션 메커니즘)
1. Attention Mechanism 등장 배경Seq2Seq 모델은 Encoder에서 Input Sequence를 Context Vector라는 하나의 고정된 크기의 벡터 표현으로 압축하고, Decoder는 이 Context Vector를 통해 Output Sequence를 만들어낸다.
self-objectification.tistory.com

(128, 32는 임의의 숫자이다)
우선 단어 "I"에 대한 Q Vector $Q_I$를 기준으로 설명해보자면, Attention Score 16, 4, 4, 16은 단어 "I"가 각각 단어 "I", "am", "a", "student"와 얼마나 연과되어 있는지를 보여주는 수치이다.
Transformer에서는 두 벡터의 내적값을 Scaling하는 값으로 K Vector의 차원을 나타내는 $d_k$에 루트를 씌운 $\sqrt{d_k}$를 사용하였다.
앞서 논문에서는 $d_k$는 $d_{model}/num\_heads$라는 식에 따라 64의 값을 가지므로 $\sqrt{d_k}$는 8의 값을 가진다.
행렬 연산 일괄 처리
모든 단어의 Q Vector에 대해 반복하여 Attention Value를 구하는 것이 아닌 행렬 연산을 사용하면 일괄 계산이 가능하다.
우선 각 단어 벡터마다 일일이 가중치 행렬을 곱하는 것이 아니라 문장 행렬에 가중치 행렬을 곱하여 Q 행렬, K 행렬, V 행렬을 구한다.

이제 Attention Score를 구해야한다.
여기서 Q 행렬($Q$)과 K행렬을 전치한 행렬($K^T$)을 곱하면 각각의 단어의 Q Vector와 K Vector의 내적이 각 행렬의 원소가 되는 행렬이 결과로 나온다.
행렬의 값에 전체적으로 $\sqrt{d_k}$를 나누어 주면 이는 각 행과 열이 Attention Score 값을 가지는 행렬이 된다. 예를 들어 "I"행과 "student" 열의 값은 "I"의 Q Vector와 "student"의 K 벡터의 Attention Score 값이다.

Attention Score 행렬을 구하였다면 이제 Attention Distribution을 구하고, 이를 사용하여 모든 단어에 대한 Attention Value를 구하여야 한다.
이는 간단하게 Attention Score 행렬에 $Softmax$함수를 사용하고, V 행렬을 곱하는 것으로 해결이 된다.
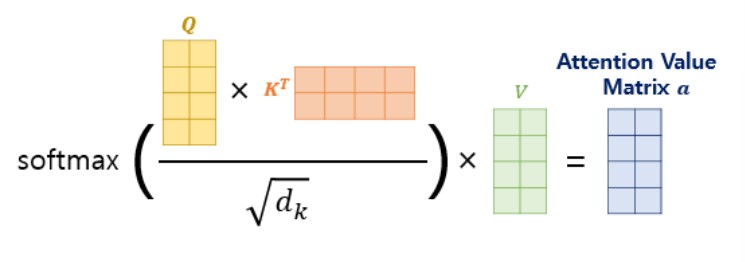
즉, 위의 과정을 수식으로 나타내면 아래의 식과 같다.
$$Attention(Q, K, V) = softmax{(\frac{Q K^T}{\sqrt{d_k}})}V$$
위의 행렬 연산에 사용된 행렬의 크기를 모두 정리하면 아래와 같다.
- 입력 문장의 길이 : $seq\_len$
- Embedding Vector Dimension : $d_{model}$
- Q, K Vector의 차원 : $d_k = \frac{d_{model}}{num\_heads} $
- V Vector의 차원 : $d_v$
- Q, K 행렬의 크기 : ($seq\_len$, $d_k$)
- V Vector의 차원 : ($seq\_len$, $d_v$)
- $W^Q, W^K$의 크기 : ($d_{model}$, $d_k$)
- $W^V$의 크기 : ($d_{model}$, $d_v$)
- $d_k, d_v$의 차원 : $\frac{d_{model}}{num\_heads}$
- ==> $softmax{(\frac{Q K^T}{\sqrt{d_k}})}V$의 결과인 Attention 행렬의 크기는 ($seq\_len$, $d_v$)
Multi - Head Attention
앞서 Attention에서는 $d_{model}$의 차원을 가진 단어 벡터를 $num\_heads$로 나눈 차원을 가지는 Q, K, V벡터로 바꾸고 Attention을 수행하였다. 논문 기준으로는 512의 차원의 각 단어 벡터를 8개로 쪼개어 64차원의 Q, K, V 벡터로 바꾸어서 Attention을 수행하였는데 $num\_heads$의 의미와 왜 $d_{model}$의 차원을 가진 단어 벡터를 가지고 Attention을 하지 않고 차원을 축소시킨 벡터로 Attention을 수 행하였는지 알아보자.
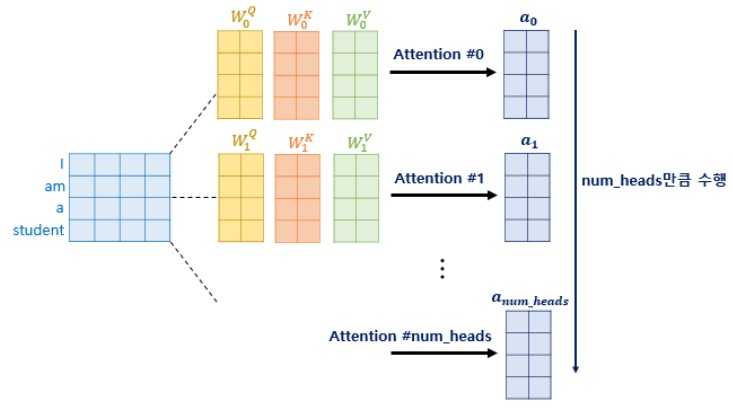
Transformer 연구진은 한 번의 Attention을 하는 것 보다 여러번의 Attention을 병렬로 사용하는 것이 더 효과적이라고 판단하였고 $d_{model}$의 차원을 $num\_heads$로 나누어 Q, K, V에 대해서 $num\_heads$개의 병렬 Attention을 수행하였다.
논문에서는 8개의 병렬 Attention이 이루어 지는데 각각 Attention Value 행렬을 Attention Head라고 부른다. 이때 가중치 행렬 $W^Q, W^K, W^V$의 값은 8개의 Attention Head마다 전부 다르다.
그럼 병렬 Attention으로 얻을 수 있는 효과는 무엇일까?
Attention을 병렬로 수행함으로써 데이터를 각각 다른 시각으로 보고 정보들을 수집하여 정보에서 놓치는 것을 없게하기 위함이다.
이제 병렬 Attention을 수행하였다면 모든 Attention Head를 연결(Concatenate)해야한다. 모두 연결된 Attention Head의 크기는 ($seq\_len$, $d_{model}$)이 된다.
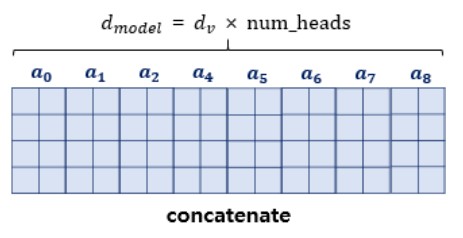
Attention Head를 모두 연결한 행렬은 또 다른 가중치 행렬 $W^0$을 곱하게 되는데, 이렇게 나온 결과 행렬이 Multi-Head Attention의 최종 결과물이다
이 때 $W^0$의 크기는 ($d_{model}$, $d_{model}$)이다. 따라서 Multi-Head Attention Matrix는 Encoder의 입력이었던 문장 행렬의 ($seq\_len$, $d_{model}$) 크기와 동일하다. 다시 말해, Encoder의 첫번째 Sub Layer인 Multi-Head Attention을 끝마쳤을 때, Encoder의 입력으로 들어왔던 행렬의 크기가 유지된다.
첫번째 Sub Layer인 Multi-Head Attention과 두번째 Sub Layer인 Position-wise FFNN을 지나면서 Encoder의 입력으로 들어올때의 행렬의 크기는 계속 유지되어야한다.
왜냐하면 Transformer는 동일한 구조의 Encoder를 쌓는 구조이기 때문에 Encoder에서의 입력의 크기가 출력에서도 동일 크기로 계속 유지되어야만 다음 Encoder에서도 다시 입력이 될 수 있기 때문이다.
Multi - Head Attention
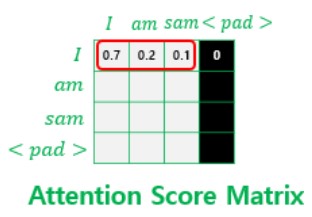
Scaled Dot Product Attention을 보면 mask 라는 값을 인자로 받아, mask 값에 -1e9라는 작은 음수값을 곱한 후 Attention Score 행렬에 더해주는 부분이 있다. 이는 입력 문장에 <pad> 토큰이 있을 경우 Attention에서 사실상 제외하기 위한 연산이다. <pad>가 포함된 입력 문장의 Self-Attention의 예제를 살펴보자.
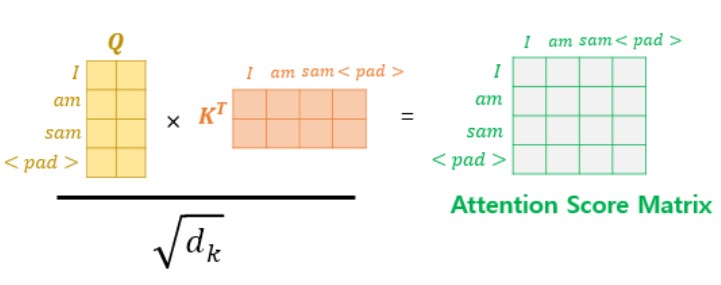
<pad>의 경우에는 실질적인 의미를 가진 단어가 아니다. 그래서 Transformer에서는 Key에 <pad> 토큰이 존재한다면 이에 대해서는 유사도를 구하지 않도록 Masking을 해주어야한다.
여기서 Masking이란 Attention에서 제외하기 위해 값을 가린다는 의미이다. Attention Score 행렬에서 행에 해당하는 문장은 Query이고 열에 해당하는 문장은 Key이다. 그리고 Key에 <pad>가 있는 경우 해당 열 전체를 Masking 해준다.
Masking을 하는 방법은 Attention Score 행렬의 Masking 위치에 매우 작은 음수값을 넣어주는 것이다. Attention Score는 $softmax$ 함수를 지나고 난 후 Value 행렬과 곱해지게 되는데 Masking 된 값이 $softmax$ 함수를 지난 후에는 해당 값이 0이 되어 단어 간 유사도를 구하는 일에 <pad> 토큰이 반영되지 않게 된다
2. Encoder의 Position - wise Feed Forward Neural Network
Position-wise Feed Forward Neural Network는 Encoder와 Decoder에서 공통적으로 가지고 있는 Sub Layer이다.
Feed Forward Neural Network
신경망에서 가장 기본적인 아키텍처 중 하나로, 입력층에서 시작해 출력층까지 순차적으로 정보를 전달하는 방식이다. 이 구조에서 정보는 오직 한 방향으로만 흐르며 순환하거나 되돌아가는 경로가 없는 신경망 구조이다.
Fully-Connected Feed Forward가 각 단어의 위치마다 적용되기 때문에 Position-wise Feed Forward Network라 표현한다.
Position-wise Feed Forward Network를 통해 각 단어의 위치마다 독립적으로 적용되어 각 위치의 단어를 비선형적으로 변환하여 정보를 더욱 풍부하게 만들어준다.

위의 그림을 수식으로 표현하면 아래의 식과 같다
$$FFNN(x)\;=\; ReLU( x W_1 + b_1) W_2 + b_2\;=\;max(0, x W_1 + b_1) W_2 + b_2$$
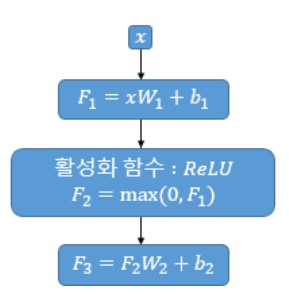
위의 그림에서 $x$는 Multi-head Attention 결과로 나온 $(seq\_len, d_{model})$의 크기를 가지는 행렬이다. 따라서 가중치 행렬 $W_1$은 $(d_{model}, d_{ff})$의 크기를 가지고, $W_2$는 $(d_{ff}, d_{model})$의 크기를 가진다. 논문에서 Hidden Layer의 크기인 $d_{ff}$는 앞서 Hyperparameter로 정의했듯이 2048의 크기를 가진다.
여기서 $W_1, b_1, W_2, b_2$는 하나의 Encoder 층 내에서는 다른 문장, 다른 단어들마다 동일하게 사용하지만 다른 Encoder 층들은 다른 값을 가진다.
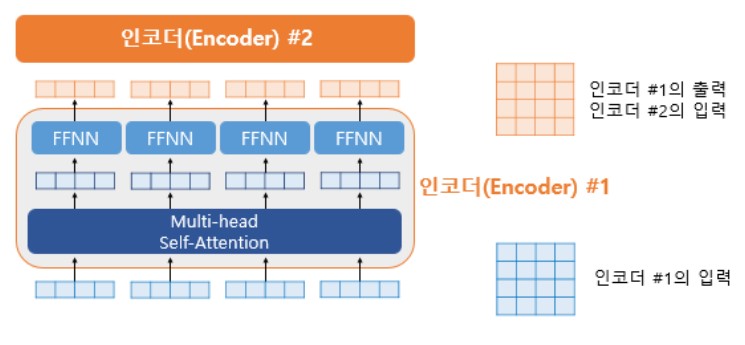
위의 그림에서 좌측의 Encoder는 각 Input Vector들이 Multi-head Attention Layer를 지나 FFNN을 통과하는 모습을 보여준다.
하나의 Encoder 층을 지난 이 행렬을 다음 Encoder 층에 전달되고, 다음 층에서도 동일한 Encoder 연산이 반복된다.
3. Residual Connecntion(잔차 연결)과 Layer Normalization(층 정규화)
Encoder의 두개의 Sub Layer에 추가적으로 사용하는 기법이 있는데 이는 Add & Norm이다. 정확하게는 잔차 연결(Residual Connection)과 층 정규화(Layer Normalization)이다.
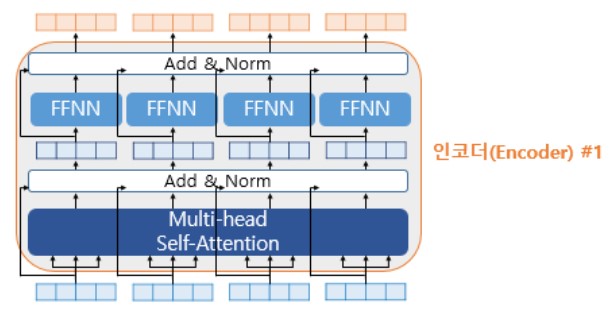
위의 그림은 Encoder의 각 Sub Layer에 Add&Norm을 추가한 그림이다. 추가된 화살표들은 Sub Layer이전의 입력에서 시작되어 Sub Layer의 출력 부분을 향하고 있는 것에 주목하면서 Residual Connection과 Layer Normalization에 대해 알아보자.
Residual Connection(잔차 연결)
Residual Connection이란 신경망에서 정보를 원래 입력값에 직접 더하여 Network의 학습을 돕는 연결 방식을 말한다. Residual Connection을 처음 도입한 ResNet(Residual Network)는 이 방식을 통해 층이 깊어질수록 발생할 수 있는 기울기 소실 문제를 효과적으로 해결하였다.
Residual Connection은 입력 $x$가 여러 층을 지나 변환된 값 $F(x)$와 입력 $x$를 그대로 더한 결과를 다음 층에 전달한다.
$$H(x) = x + F(x)$$
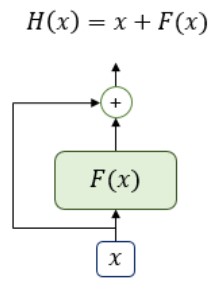
여기서 Residual의 뜻을 살펴보자면, 모델이 학습해야 할 것은 함수 $F(x)$의 출력이 아니라, $x$에 추가로 더해져야 할 잔여 정보(Residual) 즉, 입력에 더해져야 할 변화한 학습한다는 의미로 Residual Connection이라 한다.
이제 Transformer에서 Residual Connection을 살펴보자.
$F(x)$는 Transformer의 Sub Layer에 해당한다. 이를 식으로 나타내면 아래와 같다.
$$H(x) = x + SubLayer(x)$$
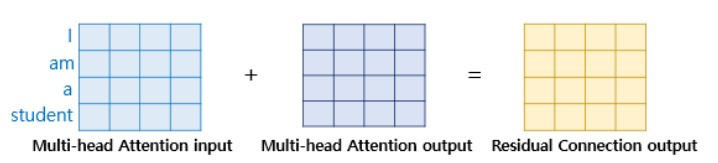
여기서 Sub Layer가 Multi-head Attention이라한다면 Residual Connection은 아래와 같다.
$$H(x) = x + Multi-head\;Attention(x)$$
Transformer에서 Residual Connection을 사용하는 이유는 아래와 같다.
- Vanishing Gradient 문제 완화
- Self-Attention과 Feed Forward Layer가 여러번 반복되면서 깊이가 상당히 깊어질 수 있는데
- 역전파 과정에서 기울기가 소실되지 않고 잘 전달될 수 있게 한다
- 중요한 정보 유지
- 입력값을 변형하지 않고 그대로 다음층에 전달하기 때문에
- 이전 층의 중요한 정보가 왜곡되지 않고 원본 상태로 다음 층에 전달된다
- 이를 통해 중요한 정보를 계속 보존하면서도 필요한 추가적인 변환($F(x)$)만을 학습할 수 있다
- 학습의 효율성 향상
- 모델은 입력의 변화를 표현하는 값(Residual)만 학습하면 된다
- 따라서 각 층에서 중요한 특성의 변화를 좀 더 빠르게 학습이 가능하다
Layer Normalization(층 정규화)
Residual Connection의 결과에 이어서 Layer Normalization 과정을 거지게 된다. Residual Connection의 입력($x$)을 잔차 연결, 층 정규화 연산을 모두 수행한 후의 결과 행렬을 $LN$이라고 하였을 때 수식은 아래와 같다.
$$LN = LayerNorm(x+SubLayer(x))$$
Layer Normalization은 Tensor의 마지막 차원에 대해 평균과 분산을 구하고, 이를 가지고 어떤 수식을 통해 값을 정규화하여 학습을 돕는다. 여기서 마지막 차원이라는 것은 Transformer에서 $d_{model}$ 차원을 의미한다.
아래 그림은 $d_{model}$ 차원의 방향을 표현한 그림이다.

Layer Normalization을 위해 화살표 방향으로 각각 평균과 분산을 구한다. 이제 Layer Normalization을 수행하면 Vector $x_i$는 $ln_i$라는 Vector로 정규화가 된다.
$$ln_i = LayerNorm(x_i)$$
이제 Layer Normalization에 대해 수식을 통해 알아보자
층 정규화는 두 가지 과정으로 진행되는데 첫번째는 평균과 분산을 통한 정규화, 두번째는 $\gamma$, $\beta$를 도입하는 것이다.
벡터 $x_i$는 아래의 식과 같이 정규화 할 수 있다.
$$\large{\hat{x}_i = \frac{x_i - \mu_i}{\sqrt{{\sigma_i}^2 + \epsilon}}}$$
이제 $\gamma$, $\beta$를 도입한다.
$\gamma$는 초기값이 1인 벡터이고, $\beta$는 초기값이 0인 벡터이다.
$\gamma$, $\beta$를 도입한 최종 수식은 아래와 같고 $\gamma$, $\beta$는 학습 가능한 parameter이다.
$$ln_i = \gamma \hat{x_i} + \beta = LayerNorm(x_i)$$
'DL > NLP' 카테고리의 다른 글
| [DL][NLP]Transformer 모델 (1) | 2024.10.29 |
|---|---|
| [DL][NLP] Attention Mechanism(어텐션 메커니즘) (1) | 2024.10.28 |
| [DL][NLP] Seq2Seq 예제 (Pytorch) (2) | 2024.10.28 |
| [DL][NLP] Seq2Seq(Seqence to Sequence) 모델 (5) | 2024.10.28 |


