Convolution Neural Network(CNN)
Convolution Neural Network(CNN) 이란 인간의 시신경을 모방하여 만든 Deep Learning 구조이다.
특히, Convolution 연산을 이용하여 Image의 공간적인 정보를 유지하고, Fully Connected Neural Network 대비 연산량을 획기적으로 줄였으며, Image Classification에서 좋은 성능을 보인다.
Image Data
우선 Image를 정형 데이터화 하는 방법을 생각해보자
정형 데이터란 컴퓨터로 식별가능한 형태로 데이터를 변환하는 것을 의미한다.
Image는 Pixel 단위로 구성되어 있고 각 Pixel은 RGB 값으로 구성되어있다.
즉, 아주 작은 색이 담긴 네모 상자가 여러개가 모여 이미지가 되고, 색은 RGB 의 강도의 합으로 표현된다
Image를 정형 데이터화 하는 방법
- 흑백 이미지의 경우 : 'Width x Height'에 흑색의 강도가 들어간 배열
- 컬러 이미지의 경우 : 'WIdth x Height x Channel(3)'의 배열로 나타낼 수 있으며, Channel은 각 R, G, B의 강도의 값

※ Channel 4 : RGB/A(Alpha 밝기)
Convolution Layer(합성곱 층)
Convolution Layer의 사용 이유
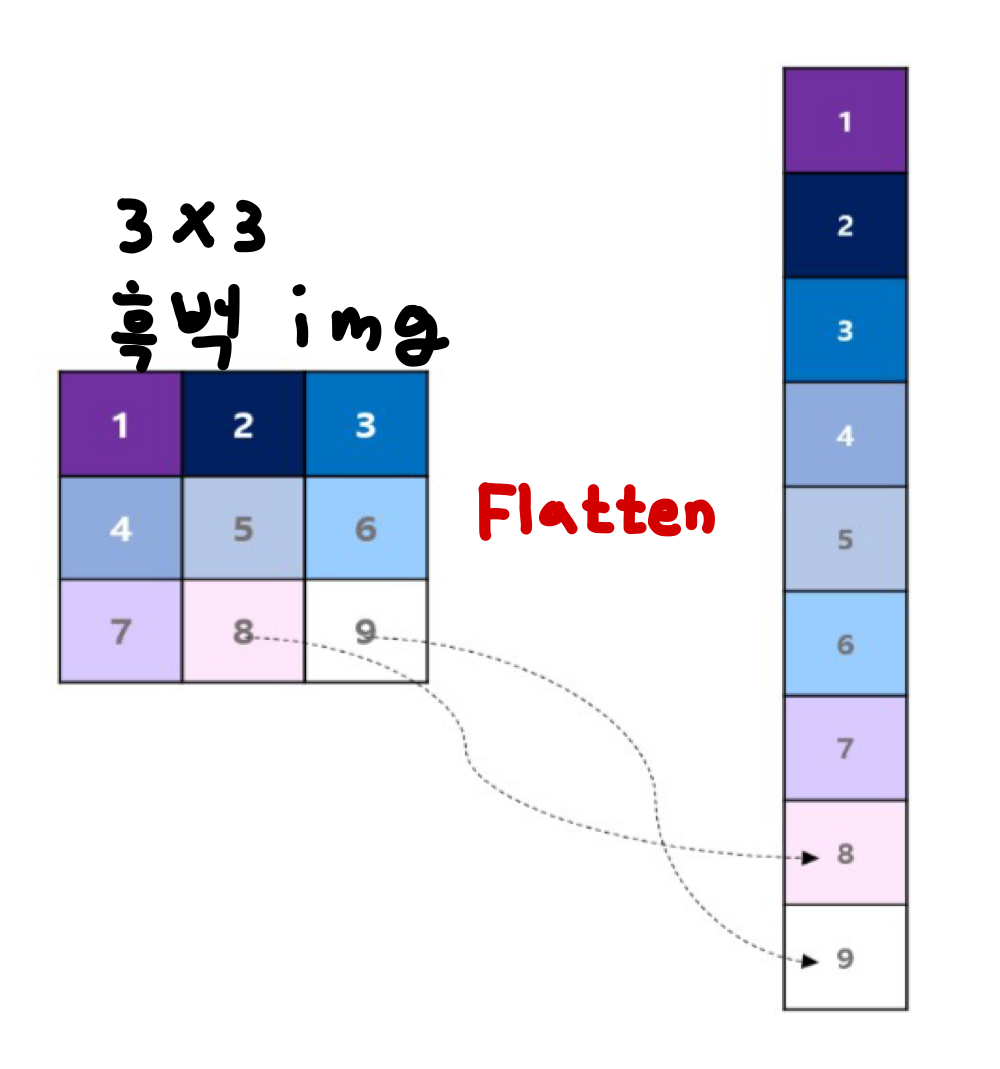
일반적으로 Deep Learning에서 이미지 데이터 값을 Flatten 하여 각 Pixel에 가중치를 곱하여 Hidden Layer로 연산 결과를 전달하여 Image를 분석한다.
이 때, Image는 데이터 특성상 각 Pixel 간 밀접한 상관관계를 가지고 있는데, 이를 Flatten 하여 분석을 하면 데이터의 공간적 구조를 무시하게 된다.
따라서, Image Data 의 공간적 특성을 유지하기 위해 Convolution Layer의 도입 이유라 할 수 있다.
Convolution(합성곱) 이란?
Convolution 이란 두 함수 $f, g$를 이용하여 한 함수($f$)의 모양이 나머지 함수($g$)에 의해 모양이 수정된 제 3의 함수($f * g$)를 생성해주는 연산으로 Computer Vision, Natural Language Processing 등 다양한 분야에 이용한다.
정의
$${\large (f * g)(t) = \int_{-\infty}^{\infty} f(\tau) \cdot g(t-\tau) d\tau}$$
$ g(t-\tau)$ : y축을 기준으로 좌우 반전 후 t 만큼 평행이동
Example)

※ Cross - Correlation
Convolution과 유사하지만 함수 g에서 y 축 반전을 거치지 않은 연산
정의
$${\large (f * g)(t) = \int_{-\infty}^{\infty} f(\tau) \cdot g(t + \tau) d\tau}$$

Convoltion Layer 에서의 연산은 정확하게는 Cross - Correlation을 사용한다.
하지만, CNN에서는 가중치를 학습하기 때문에 Convolution, Cross - Correlation을 구분할 필요는 없다.
역전파를 통해 가중치를 학습하는 과정을 강조하고자 Convolution으로 사용한다.
Convolution Layer 계산방법
Sliding Window 방식으로 Weight x Input 값에 Activation Function을 취하여 Hidden Layer에 전달한다
Example)
- Image : Input (흑백 이미지 or 컬러 이미지 -> Pixel 값)
- Filter(Kernel, Window) : Image를 투영하여 Convolution 연산 수행

※ Convoltion Layer의 Convolution 과정은 Input Data의 일부만 Hidden Layer와 연결되는 Local Connectivity
아래 그림은 Fully Connected Layer와 Convolution Layer의 Connectivity를 보여주는 그림입니다

Stride & Padding
- Stride(스트라이드) : Filter를 Input이나 Feature map에 적용할 때 이동하는 간격
- Padding(패딩) : 반복적으로 Convolution 연산을 적용했을 때 Feature Map의 크기가 작아짐을 방지하는 것과 모서리 부분의 정보 손실을 줄이고자 주변을 0으로 채워넣는 것
- Valid Padding : Padding을 추가하지 않은 형태
- Full Padding : Input Data의 모든 원소가 Convolution 연산에 같은 비율로 참여
- P = F - 1
- Same Padding : Output 크기를 Input 크기와 동일하게 유지
- P = $\frac{F- 1}{2}$

오른쪽 그림은 Padding 없이 Convolution 연산을 수행했을 때 각 Pixel이 Filter의 연산에 사용된 횟수를 나타낸다
모서리 부분이 이용이 적게 되어 모서리 부분 정보손실이 발생할 수 있다
앞서 설명한 Convolution 설명은 Input이 흑백 이미지임을 가정하여 설명하였습니다.
이제 Input이 컬러 이미지일 때를 설명하겠습니다.
Input이 컬러 이미지일 경우 Convolution Layer
- 흑백 이미지와 달리 Filter의 Channel이 3
- RGB 별로 각각 다른 가중치로 Convolution 연산 수행 후 합산

※ Filter의 Channel이 3이라는 것이 Filter의 수가 3개라는 것은 아니다(Filter의 수는 1개)
Filter의 개수가 2개 이상인 Convolution 연산
Filter가 2개 이상이면 각각은 특성 추출 결과의 Channel이 된다

Convolution Layer를 지난 Image Data의 크기는 아래와 같습니다.
Input Data : $W_1 \times H_1 \times D_1$
Hyper Parameter : Filter 수 K, Filter 크기 F, Stride S, Padding P
Output Data : $W_2 = \frac{W_1 - F + 2P}{S} + 1$, $H_2 = \frac{H_1 - F + 2P}{S} + 1$, $D_2 = K$
Pooling Layer & Flatten Layer
Pooling Layer
데이터의 공간적인 특성은 유지하면서 크기를 줄여주는 층으로 연속적인 Convolution Layer 사이에 주기적으로 적용하는 연산이다.
공간적 특성은 유지하면서 크기를 줄여 특정 위치에서 큰 역할을 하는 Feature를 추출하거나, 전체를 대변하는 Feature를 추출할 수 있다.
또한, 크기를 줄여 학습할 가중치를 크게 줄이게 되고 Over-fitting을 해결한다.
MaxPooling, AveragePooling, MinPooling이 있지만 주로 Max Pooling을 사용하는데 이는 Average Pooling은 각 Kernel 값을 평균화시켜 중요한 가중치를 갖는 값의 특성을 희미해지게 할 수 있기 때문이다.
Pooling Layer에서는 합성곱에서의 Filter처럼 정해진 Stride로 움직이며 Max / Average 값을 추출

Pooling Layer를 지난 Image 데이터의 크기는 아래와 같습니다.
Input Data : $W_1 \times H_1 \times D_1$
Hyper Parameter : Filter 크기 F, Stride S
Output Data : $W_2 = \frac{W_1 - F}{S} + 1$, $H_2 = \frac{H_1 - F}{S} + 1$, $D_2 = D_1$
Flatten Layer
Convolution Layer, Pooling Layer에서 Feature를 추출한 다음, 추출한 Feature를 Output Layer(Fully Connected Layer)에 연결하여 어떤 Image인지 분류하는 Layer이다.
즉, Flatten Layer 이후로는 일반 신경망과 동일하다.
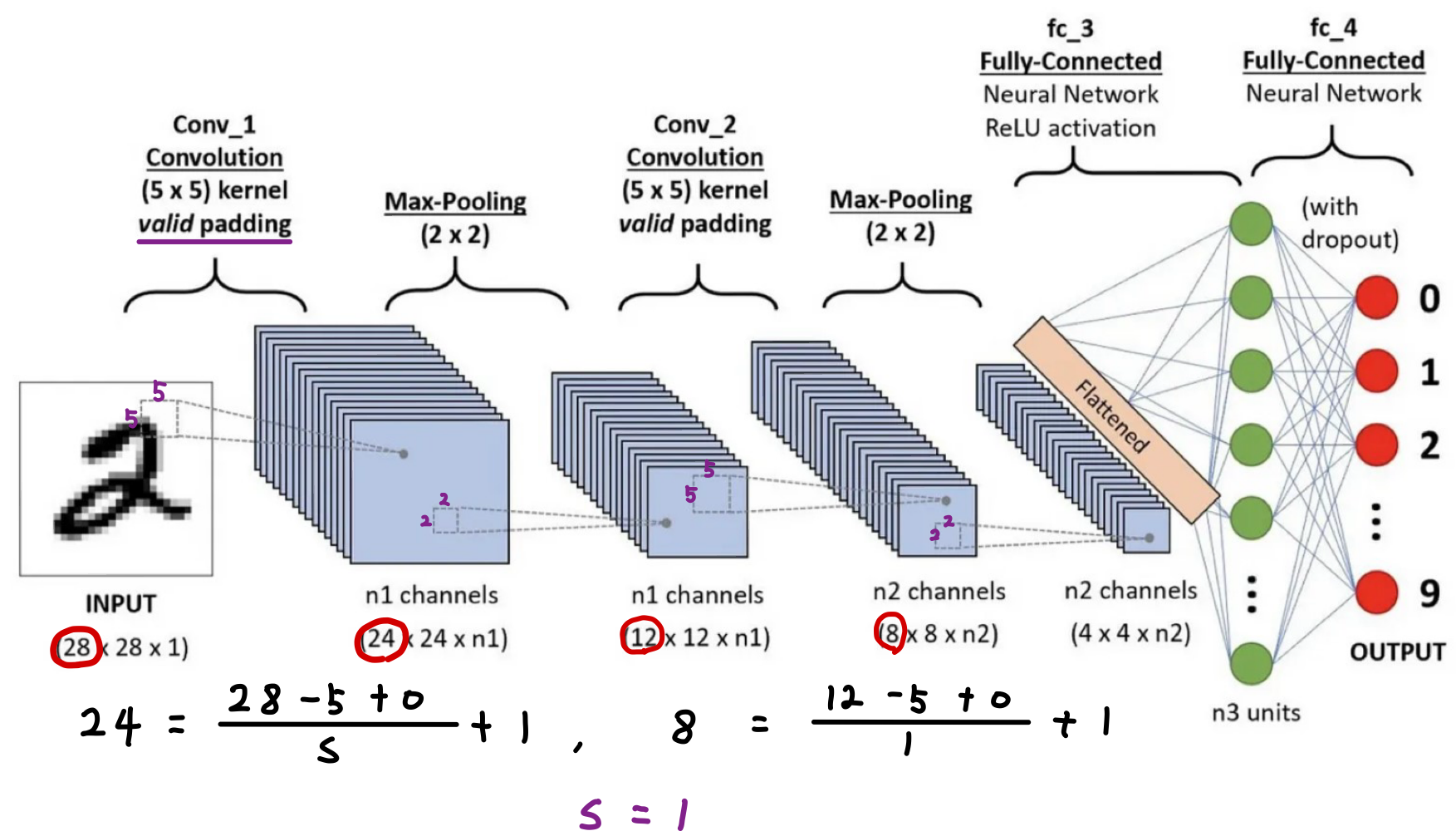
아래 그림은 CNN의 전체 구조를 나타내는 그림이다.

아래 그림은 CNN의 전체 과정을 나타내는 그림입니다
'DL > CNN' 카테고리의 다른 글
| [DL][CNN] LeNet-5 (1) | 2025.01.15 |
|---|---|
| [DL][CNN] 설명 가능한 AI (Explainable Artificial Intelligence, XAI)와 Feature Map 시각화, PyTorch 예제 (1) | 2025.01.15 |
| [DL][CNN]전이학습의 미세조정 기법(Fine - Tuning) 개념 및 PyTorch 예제 (0) | 2025.01.14 |
| [DL][CNN]전이학습(Transfer Learning) 및 특성추출(Feature Extraction) 정리 ,CNN(resnet18) PyTorch 예제 (0) | 2025.01.14 |
| [DL][CNN] CNN(Convolution Neural Network) PyTorch 예제 (0) | 2024.08.15 |



