LightGBM
XGBoost와 LightGBM은 Decision Tree 알고리즘 기반의 대표적인 Boosting 앙상블 기법입니다
여기서 LightGBM은 시간적 한계를 보완한 알고리즘입니다
Node의 split을 균형 트리 분할(Level - wise Tree Growth) 방식이 아니라 최대 Loss를 가진 Node를 중심으로 계속 분할하는 Leaf 중심 트리 분할 (Leaf-wise Tree Growth)방식을 사용합니다
이 방식을 통해 Tree가 깊어지기 위해 소요되는 시간과 메모리를 절약할 수 있습니다
 |
|
Motivation & Idea
Motivation
기존의 Boosting 알고리즘은 B번의 반복 학습 때마다 전체 데이터 셋을 scan하여 모든 Split Point에 대한 Information Gain을 평가하여 Split을 진행하는데 이 과정에서 대부분의 계산 비용이 발생
Idea
GOSS(Gradient - Based One Slide Sampling)
서로 다른 Gradient를 가지는 Data Instance는 Information Gain 계산에서 각각 다른 역할을 하기 때문에, 큰 Graident를 가지는 데이터는 놔두고, 작은 Gradient를 가지는 데이터는 Drop(랜덤으로 몇개만 Sampling)
EFB(Exclusive Feature Bundling)
Sparse한 Feature space에서 대체로 많은 Feature들이 Mutually Exclusive하다(동시에 0이 되지 않는) 이러한 Exclusive한 Feature들을 Bundling(묶음)해도 성능에 큰 영향을 주지 않는다
따라서 탐색해야하는 Feature의 수를 감소시킨다
GOSS(Gradient - based One Slide Sampling)
GOSS 알고리즘에 대해 설명하도록 하겠습니다
1. Input
Input에서 중요하게 봐야할 것은 HyperParametera,b입니다
- a
- Gradient 절대값이 큰 데이터 포인트의 비율
- 상위 a%의 데이터 포인트를 선택(
- 이 데이터 포인트들은 중요도가 높기 때문에 가중치 조정을 하지 않음
- b
- Gradient 절대값이 작은 데이터 포인트 중 선택할 비율
- 하위 (1−a)%의 데이터 포인트 중 Random으로 b%를 선택
- 이 데이터 포인트들은 중요도가 낮기 때문에 이후 가중치 조정
이 때 하위 (1−a)%에서 선택된 b%의 데이터 포인트의 가중치에 대해서는 조정 계수라 부르는 상수 1−ab를 곱해주어 조정해주게 됩니다.
이 상수는 작은 Gradient 데이터 포인트가 원래 데이터 셋의 Gradient 분포와 유사한 영향을 미치도록 조정하는 역할을 합니다
2. 초기 값 설정
fact←1−ab로 조정계수 설정 하고, 상위 a% 개수와 하위 b% 개수를 설정합니다
3. 아래 과정을 Iteration d번 반복
Gradient g←loss(I,preds)를 통해 구하고 절대값이 큰 순으로 정렬합니다
그 후 각 데이터 포인트에 대한 가중치 w←{1,1,⋯}를 초기와 합니다
topSet : 절대값이 큰 순으로 정렬된 Graident 중 상위 a%개
randSet : 절대값이 큰 순으로 정렬된 Graident 중 하위 (1−a)% 중 b%개를 Random Pick
usedSet : 상위 a%개와 하위 (1−a)% 중 $b&% 중 Random으로 선택한 데이터 포인트를 모두 선택
w[randSet]×=fact : 조정계수(fact=1−ab)를 하위 데이터 포인트들의 가중치에 곱하여 가중치 조정
newModel←L(I[usedSet],−g[usedSet],w[usedSet]) : 새로운 모델을 학습시키는 단계입니다
선택된 데이터 포인트 I(usedSet) 에 대해 −g[usedSet], w[usedSet]을 반영하여 학습합니다
−g[usedSet]은 선택된 데이터 포인트의 Gradient의 반대방향(Loss를 최소화하기 위해)을 반영하는 것이고,
w[usedSet]은 선택된 데이터 포인트의 가중치(조정계수로 조정 or 조정 x)를 반영합니다
3의 과정을 1 ~ Iteration d번 반복하면 GOSS 알고리즘이 완료됩니다
EFB(Exclusive Feature Bundling)
EFB(Exclusive Feature Bundling)는 2개의 알고리즘을 통해 수행됩니다
- 현재 Feature Set에서 어떤 Feature를 하나의 Bundle로 묶을 것인지 결정하는 과정(Greedy Bundling)
- Bundling 된 Feature들을 하나의 값으로 표현하는 과정(Merge Exclusive Feature)
1. Greedy Bundling
현재 Feature Set에서 어떤 Feature를 하나의 Bundle로 묶을 것인지 결정하는 과정인 Greedy Bundling은 위에서 설명드렸다듯이 Mutually Exclusive한 Feature들을 하나의 Bundle로 묶는 방법입니다.
이는 Graph이론에서 Graph Coloring 방법으로 해결하게 됩니다
여기서 Minimum Vertex Coloring은 NP-hard 문제이므로 Greedy 알고리즘을 사용하기 때문에 Greedy Bundling이라 부릅니다
G : 각 Feature를 Vertex로 하고 Feature간 Conflict를 수를 Edge의 Weight로 하는 Graph
K : Bundle 내에서 최대로 허용되는 Conflict
Cut-off γ라고도 하며 (전체 데이터 수 X γ)로 사용한다
searchOrder←G.sortByDegree() : Greedy 알고리즘을 위해 각 Vertex(feature)의 Degree(Conflict 수)를 내림차순으로 정렬

ConflictCnt(bundles[j],F[i]) : 이미 Bundle에 포함된 Feature들 추가할 Feature와의 Conflict 계산
bundlesConflict[i→j] : 이 부분은 논문에서 오타가 난거같습니다
Bundle내의 Feature들의 Conflict 입니다
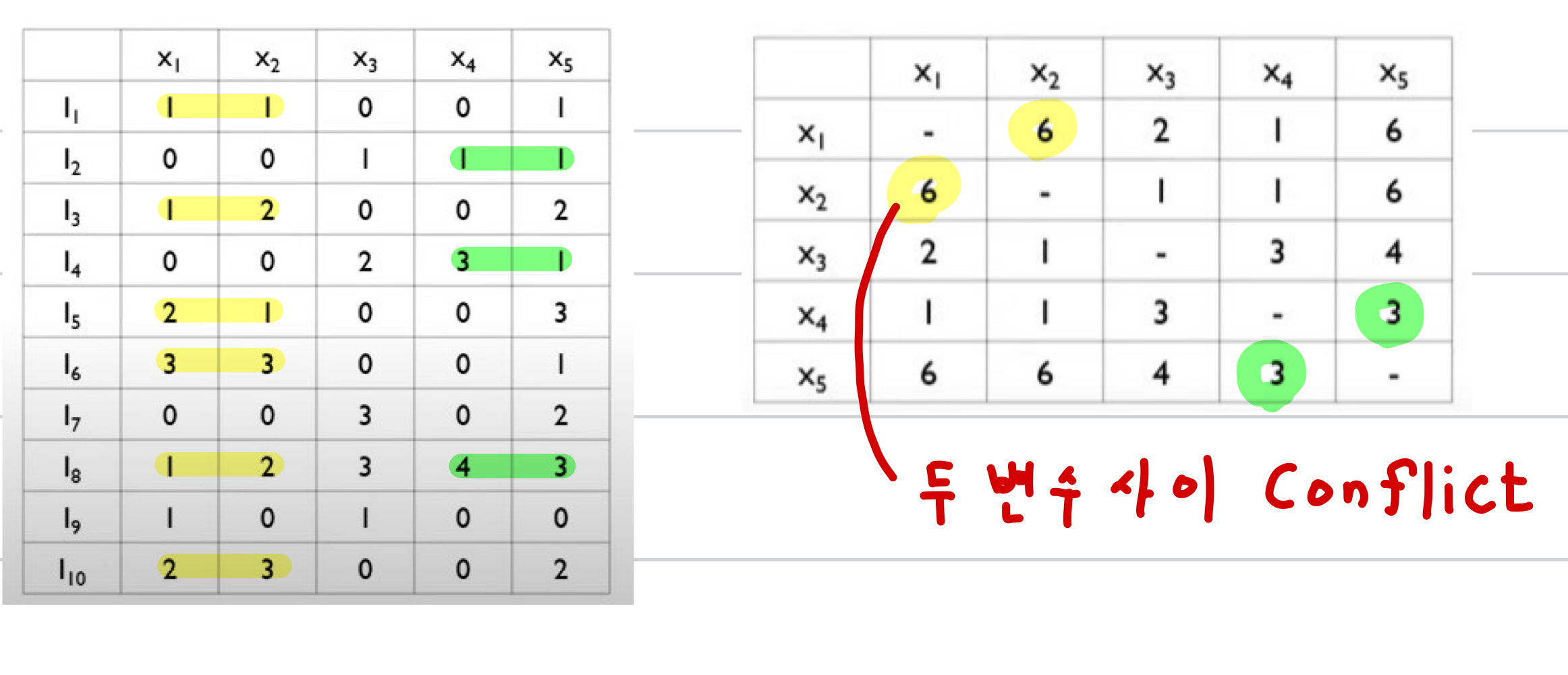
우선 각 Feature끼리의 Conflict Matrix를 생성하고 이를 기반으로 Graph를 그립니다
위의 Matrix에 기반한 Graph는 아래와 같습니다
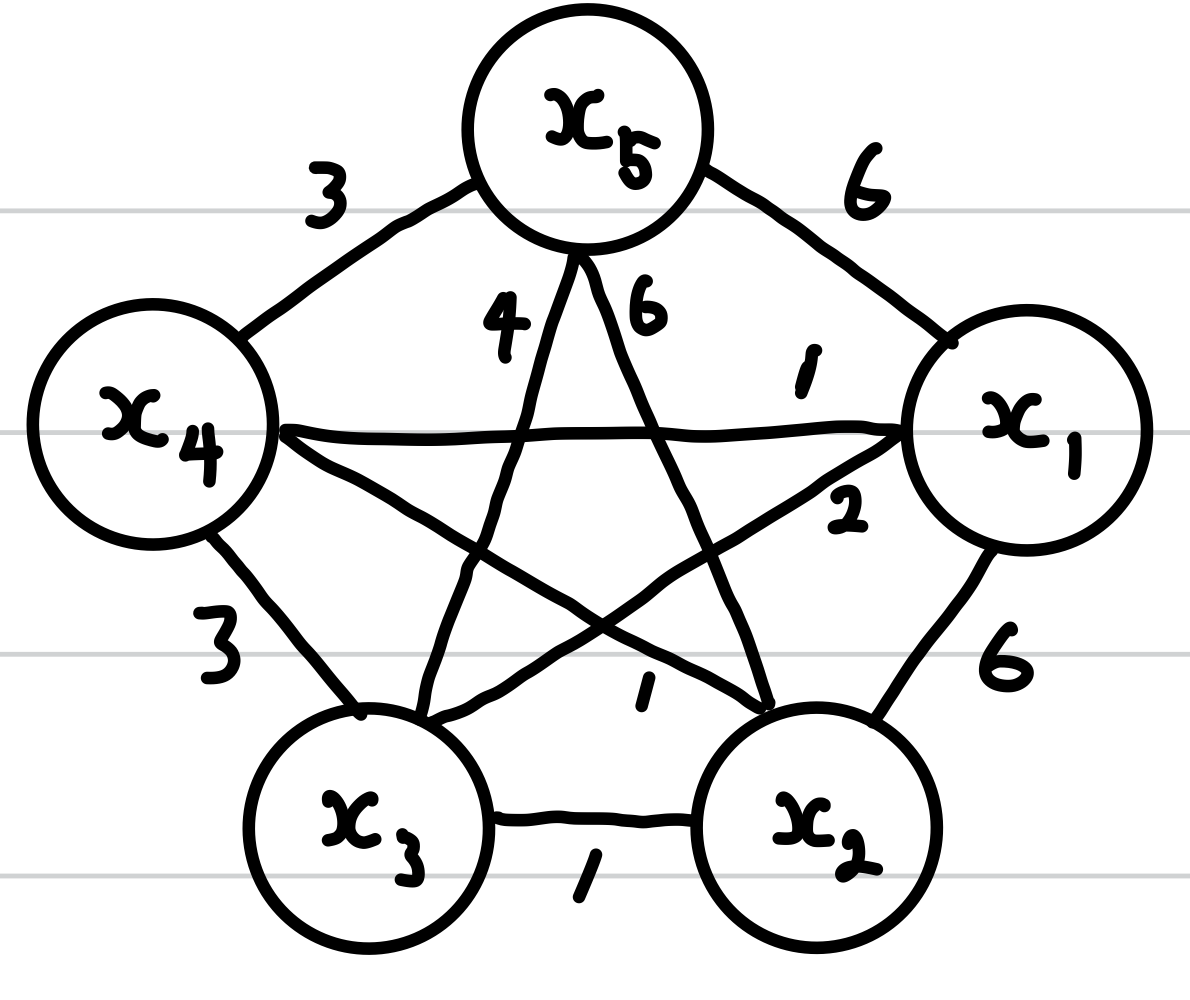
앞서 설명했듯이 Degree를 기준으로 정렬합니다

그럼 이제 Algorithm 3의 searchOrder=x5,x1,x2,x3,x4가 되고 forloop를 수행합니다
(이때 Cut-off γ = 0.2로 설정하면 K = 10 X 0.2 = 2)
- i=x5 : len(bundles)=0이므로 bundles[1]=x5
- i=x1 : cnt=Conflict(bundles[1],x1)=6+bundlesConflict[i]=0≥2
- 따라서 x1을 bundles[2]에 추가
위 과정을 정렬된 Feature Set에 대해 반복하면 Bundle을 얻을 수 있다
2. Merge Exclusive Feature
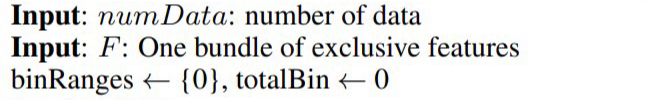
Bundle에 포함된 Feature들을 하나의 값으로 Merge하기 위한 Input 입니다
각 Feature의 bin(범위, min ~ max)를 이용하여 Merge를 진행합니다

Bundle에 포함된 각 Feature(finF)의 bin 값을 더하여 binRanges에 저장합니다
그리고 Merge 한 값을 저장할 새로운 변수 newBin을 정의합니다
아래에서 예시를 들어보겠습니다
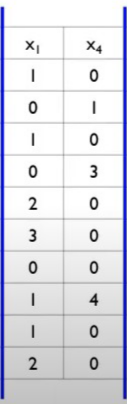
F=x1,x4
F[1](x1)의 bin은 [0,3]이고, F[2](x4)의 bin은 [0,4]입니다
따라서 binRanges⇒[0,3]⇒[0,3,7]이 됩니다
(여기서 numBin은 bin의 max의 값입니다)
그리고 Merge 한 값을 저장할 새로운 변수 newBin을 정의합니다

Merge하는 과정입니다
Bundle에 포함된 Feature의 각 데이터를 순회하면서 Merge를 수행합니다
예시를 통해 보여드리도록 하겠습니다

'ML > Ensemble' 카테고리의 다른 글
| [ML][Ensemble]XGBoost(Extreme Gradient Boost) (4) | 2024.07.04 |
|---|---|
| [ML][Ensemble]Gradient Boosting Machine(GBM) (1) | 2024.07.02 |
| [ML][Ensemble] AdaBoost(아다부스트, Adaptive Boosting) (0) | 2024.06.26 |
| [ML][Ensemble] Random Forest(랜덤 포레스트), OOB(Out Of Bag) (0) | 2024.06.25 |
| [ML][Ensemble] Ensemble Learning(앙상블 학습), Bagging(배깅),Boosting(부스팅) (0) | 2024.06.25 |



