[Optimization] Gradient Descent(경사하강법)
! Optimization에 대해서 이제 처음 접해보시는 분은 Optimization 정의 먼저 보고 오시면 좋습니다 ! [Optimization] Optimization 정의Optimization(최적화) 란?Optimization이란 최소한의 Cost로 최적의 답을 찾는 과
self-objectification.tistory.com
앞선 글에서 간략하게 Gradient Descent 기본 개념에 대해 보았습니다
그럼 이번 글에서는 여러 Gradient Descent 대해서 보도록 하겠습니다 !
※ Notation
Epoch
인공신경망에서 전체 데이터 셋에 대해 Forward, Backward 과정을 한번 거친 것
즉, 전체 데이터 셋에 대해 한번 학습 완료한 것
Batch(Full - Batch)
1번의 Epoch에 사용하는 데이터 셋(전체 데이터 셋)
만약 Full Batch를 통해 학습한다면 1 Iteration = 1 Epoch
$$Train\;Set = (X, y) = \{(x_1, y_1), (x_2, y_2), \cdots, (x_n, y_n)\}$$
Mini - Batch
Full Batch를 사용하면 계산량이 너무 많아지기 때문에 데이터 셋을 일정한 크기로 나누어 학습을 진행
Full Batch를 사용할 때 보다 부정확할 수 있지만 계산 속도가 훨씬 빠르기 때문에 같은 시간에 더 많은 step을 진행할 수 있으며 여러번 반복할 경우 Batch로 처리한 결과로 수렴
$$Mini\;Batch\;of\;size\;M\;:\; (X^{(M)}, y^{(M)}) = \{(x_m, y_m), \cdots , (x_{m+M-1}, x_{m+M-1})\}$$
Iteration
1 Epoch 내에서 진행되는 Parameter Update 횟수(Mini Batch 사용)

그럼 이제 여러가지 Gradient Descent 방법을 공부해보도록 하겠습니다 !
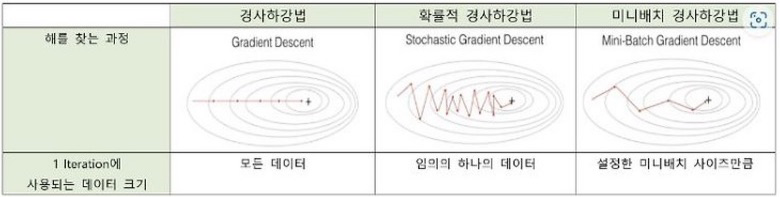
1. Full Batch Gradient Descent
앞서 설명드렸던 것과 같이 Full Batch를 모델 학습에 사용하는 방법입니다
Parameter Update의 정확도는 높지만 계산량이 많아 느릴 수 있습니다
또한, 대용량 데이터가 메모리에 한번에 load 되지 못할 수 있습니다
$$ \theta_{k+1} \leftarrow \theta_{k} - \eta[ \frac { \partial L ( \theta ; X , y ) } { \partial \theta } ]_{ \theta = \theta_{k}}$$
2. Mini Batch Gradient Descent
앞서 설명드렸던 것과 같이 Mini Batch를 모델 학습에 사용하는 방법입니다
$$\theta_{t+1} \leftarrow \theta_{t} - \eta [ \frac { \partial L ( \theta ; X^{(t)} , y^{(t)})} {\partial \theta}]_{\theta = \theta_{t}}$$
$$(X^{(t)}, y^{(t)}) = \{(x^{(t)}, y^{(t)}), (x^{(t+1)}, y^{(t+1)}), \cdots, ( x^{(t+B-1)}, y^{(t+B-1)} )\}$$
이때, B는 Mini Batch size이고 t는 한 Epoch 내에서 t번째 Iteration임을 의미합니다
3. Stochastic Gradient Descent(SGD, 확률적 경사 하강)
Mini Batch를 모델 학습에 사용하는 방법이지만 Mini Batch Size = 1일 때 SGD라고 합니다
하나의 sample 만을 사용하기 때문에 계산 비용이 적고 빠르게 최적값에 근사할 수 있다라는 장점이 있지만 noisy한 Gradient(True Gradient와 다른 방향)가 될 수 있어 불안정합니다
$$\theta_{t+1} \leftarrow \theta_{t} - \eta [ \frac { \partial L ( \theta ; x_t , y_t)} {\partial \theta}]_{\theta = \theta_{t}}$$
4. Average Stochastic Gradient Descent(ASGD)
일반적인 SGD와 달리 Iteration동안 Update된 가중치들의 평균을 사용하여 최종 가중치를 결정하는 방법입니다
각 Iteration에서 Update된 가중치를 모두 기록하여 평균을 적용합니다
불규칙한 데이터 분포나 noise가 있는 데이터에서 SGD보다 안정적이고, 수렴속도를 향상 시킬 수 있습니다
$$\theta_{t+1} \leftarrow \theta_{t} - \eta [ \frac { \partial L ( \theta ; X^{(t)} , y^{(t)})} {\partial \theta}]_{\theta = \theta_{t}}$$
평균화 단계
$$\bar{\theta}_t = \frac{1}{T} \sum \limits_{i=1}^{T} \theta_i$$
ASGD에서 사용하는 $\bar{\theta_t}$는 1 ~ t 번째 Iteration까지의 Parameter 값의 평균을 나타낸다. 즉, 매 Iteration마다 평균을 갱신해 나가며 최종적으로 $\bar{\theta}_T$를 최적화된 Parameter로 사용한다.
※ 점진적 계산
실제로 $\bar{\theta_t}$를 효율적으로 계산하기 위해서는 점진적 업데이트를 사용한다.
1. t = 1일 때 : $\bar{\theta_1} = \theta_{-1}$
2. t > 1 일 때 : $\bar{\theta_t} = \frac{t-1}{t} \bar{\theta}_{t-1} + \frac{1}{t} \theta_t$
이로써 여러가지 Gradient Descent 방법을 알아보았습니다
보편적으로 많이 쓰이는 Mini - Batch Gradient Descent, SGD는 Parameter 변경 폭이 불안정한 문제를 가지고 있습니다
이에 따라 학습속도(Velocity), 운동량(Momentum)을 조정하는 Optimizer들이 많이 나왔습니다
다음에 공부할 주제는 Velocity와 Momentum을 조정하는 Optimizer(Adagrad, Adam, RMSProp 등) Opimizer 입니다 !
'Optimization' 카테고리의 다른 글
| [Optimization]Adam(Adaptive Momentum Estimation), Adamax (4) | 2024.06.13 |
|---|---|
| [Optimization]Adagrad(Adaptive Gradient), RMSProp(Root Mean Squared Propagation), Adadelta(Adaptive delta) (2) | 2024.06.12 |
| [Optimization]Momentum, Nesterov Accelerated Gradient(NAG) (0) | 2024.06.10 |
| [Optimization] Gradient Descent(경사하강법) (1) | 2024.06.08 |
| [Optimization] Optimization 정의 (1) | 2024.06.08 |


